Subscribe to our newsletter
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.


Spring cleaning isn’t just for closets. While you were clearing the backlog, we were shipping new updates that make Kubernetes optimization easier, faster, and more streamlined.
This blossoming season, PerfectScale by DoiT delivered a wave of updates across visibility, automation, governance, and platform experience, all guided by our core principle: K8s optimization should be safe, data-driven, and aligned with how your team operates.
Let's break it down.
Good optimization starts with good data. But the gap between "having metrics" and "knowing what to do with them" is the most challenging part. That is why we focused on closing that gap, giving you sharper, more actionable visibility to point you exactly where it matters.
Memory issues in Kubernetes are sneaky. Your workload might look fine on the p99 chart, but one short-lived spike can trigger an OOM issue, restart your pod, and turn healthy metrics into a bad user experience. Lack of visibility into peak memory utilization creates a blind spot: you either over-provision “just in case” or find out about the spike when it’s already breaking things.
PerfectScale now shows Max memory directly in the CPU and Memory utilization charts, capturing the absolute peak, including OS page cache and buffers. This means you can see exactly how close your workloads come to their memory limits and make informed decisions to prevent OOMs.
Node-level optimization is a critical piece of the optimization puzzle, but it gets complicated when some pods can't be moved, becoming blockers. Such pods may be effectively "stuck", as they can't be evicted during node scaling or rebalancing, limiting your underlying infrastructure optimization efficiency.
PerfectScale now provides an exceptional Unevictable Pods visibility, making it easy to identify such constraints and understand their impact on your infrastructure. With this view you seamlessly identify and address scale-down blockers, improve bin-packing, maximize the efficiency of your cluster autoscaling solution (like Karpenter, or Cluster Autoscaler), and ultimately optimize your K8s cloud costs.
How do you choose the right node type for your workloads? It’s not just CPU and memory, and even that part is tricky. Scheduling rules, DaemonSet overhead, and workload fit matter if you want to avoid overpaying or risk unscheduled pods.
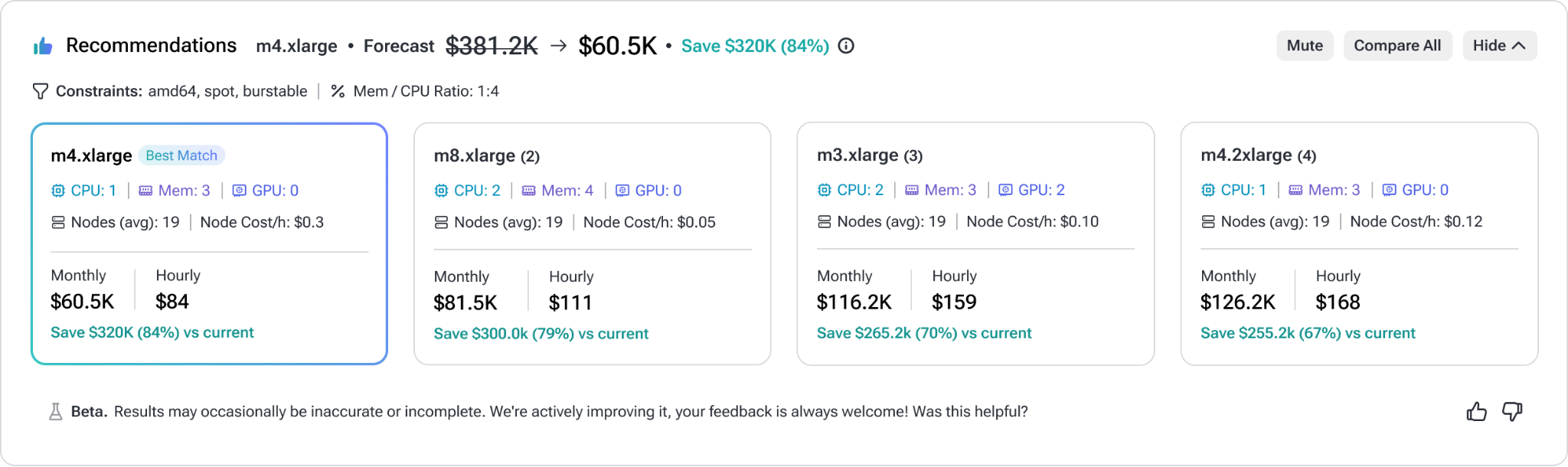
We’ve enhanced node recommendations to empower you with an even more comprehensive solution and make node group optimization more flexible and easier to act on. PerfectScale now provides multiple recommendation options for each node group across compatible instance families, helping you select the optimal machine for your workloads while clearly understanding the savings impact.
Autonomous optimization is powerful, but only if teams adopt it. The easier it is to get started, the faster you see results. That is why we introduced Automation via UI configuration, so users can seamlessly adapt it in a minute.
Not every team wants or is ready to start with CRDs. Some want to validate the concept first, see the impact quickly, and build confidence before investing time into advanced configurations.
UI-based automation configuration solves that. You can now enable autonomous optimization for entire clusters or specific workloads directly from the PerfectScale platform, with just a few clicks. No YAML, no CRDs. Just toggle it on and let PerfectScale start optimizing. Once you're ready for more control, you can seamlessly transition to a traditional CRD-based configuration without losing your setup.
In addition, we also updated automation statuses across the platform to give you clearer visibility into what's happening with each workload: actively optimized, pending, limited by a rule, or waiting for sufficient data.
Managing PerfectScale agents across multiple clusters, installing, upgrading, and keeping versions in sync, can become its own maintenance project, especially at scale.

The PerfectScale Operator is a Kubernetes operator that manages the lifecycle of PerfectScale components, including the exporter, automation agent, and other components. It supports three upgrade modes:
This enables teams to choose the level of control that matches their change management practices and perfectly aligns with the existing workflow.
As teams scale their K8s environments, they need a way to seamlessly integrate optimization governance into their existing GitOps workflows. This quarter, we delivered a couple of features that expand PerfectScale’s platform capabilities around exactly this.
Optimization policies define how PerfectScale should right-size your workloads, whether your goal is maximum savings or maximum headroom. Until now, these were managed through the UI, which works fine for individual clusters. However, when you are managing dozens of clusters, you may need a more advanced approach.
Optimization Policy with CRD allows you to define policies at the cluster, namespace, or workload directly through Kubernetes manifests, enabling more granular control over optimization while seamlessly integrating with your existing GitOps workflows.
In dynamic environments, such as Spark jobs, Airflow DAGs, or CI pipelines, workloads often span multiple namespaces, making it difficult to apply consistent optimization and automation policies.
Cross-namespace workload grouping solves this friction by allowing you to consolidate related workloads under a single target namespace using labels. Define your automation configuration once in the target namespace, and PerfectScale applies it to all grouped workloads, ensuring consistent optimization and reducing manual overhead.

Managing large-scale Kubernetes environments with dozens of clusters requires more sophisticated approaches to manage them effectively, meaning you need a way to organize, filter, and navigate your clusters to get the view or dashboard that reflects how your team thinks about infrastructure.
Cluster Labels via CRD lets you define cluster labels directly through Kubernetes manifests and manage them as code. This helps maintain consistency across clusters while fitting into your existing automation pipelines.
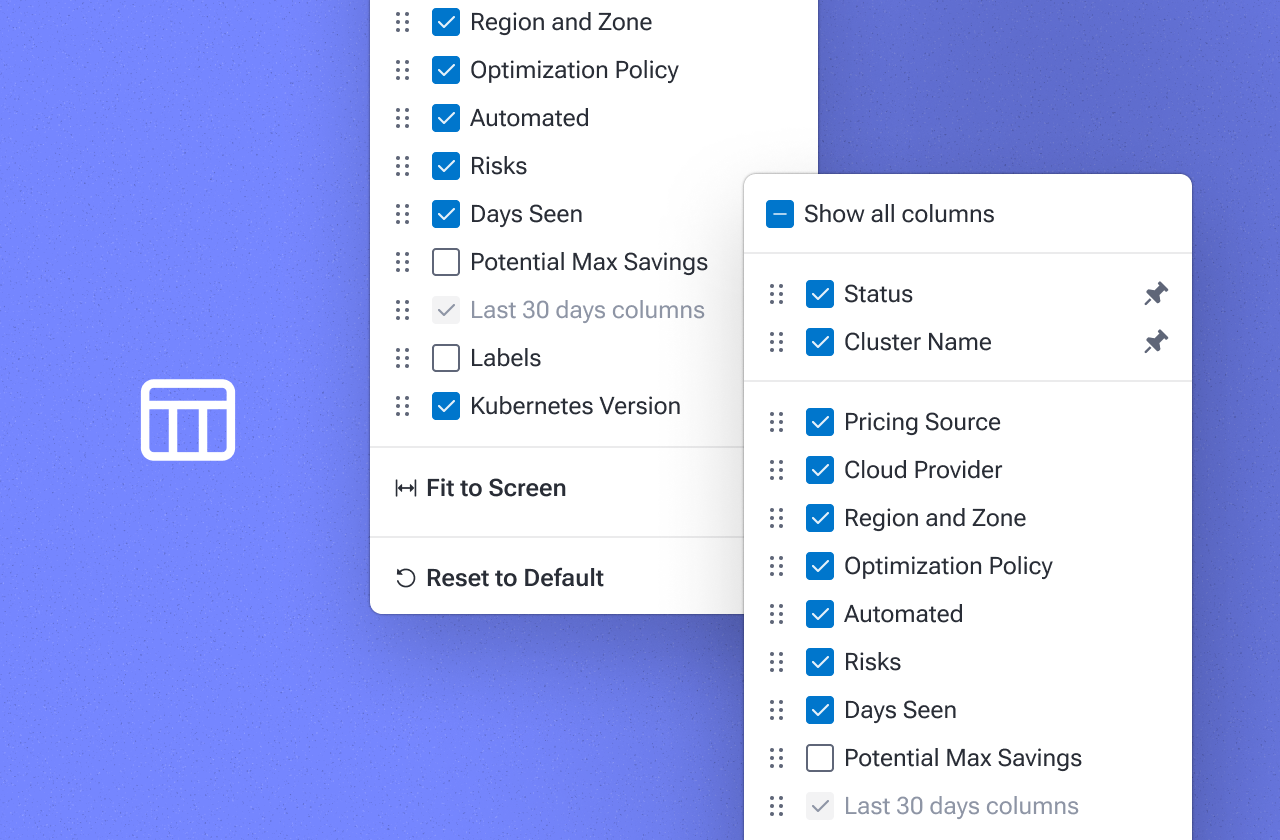
Every team looks at its optimization data differently. A platform engineer might care about node idle costs, while an SRE focuses on resiliency risks. But with fixed table layouts, they both are forced to scroll tables and columns to find what really matters.
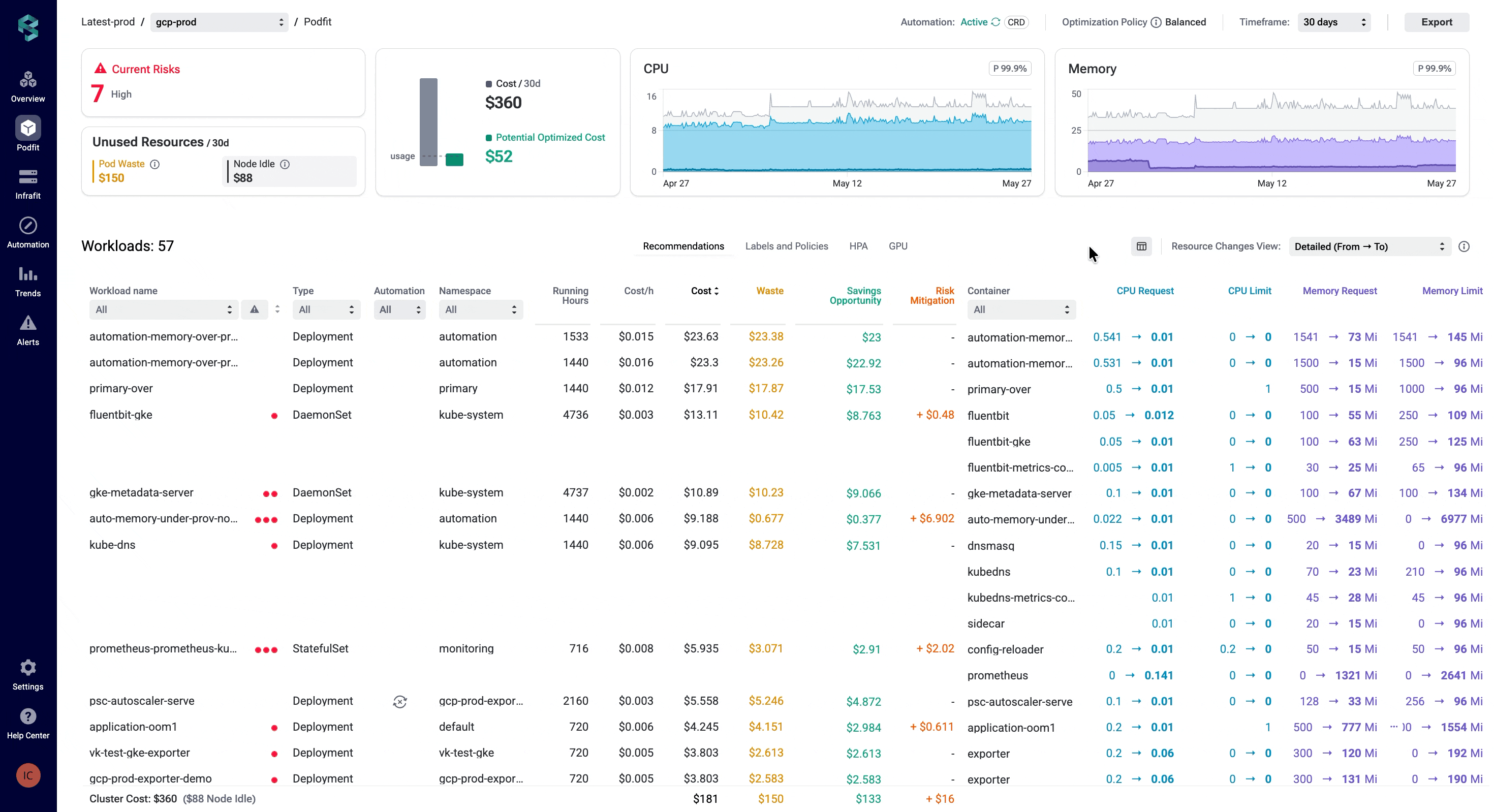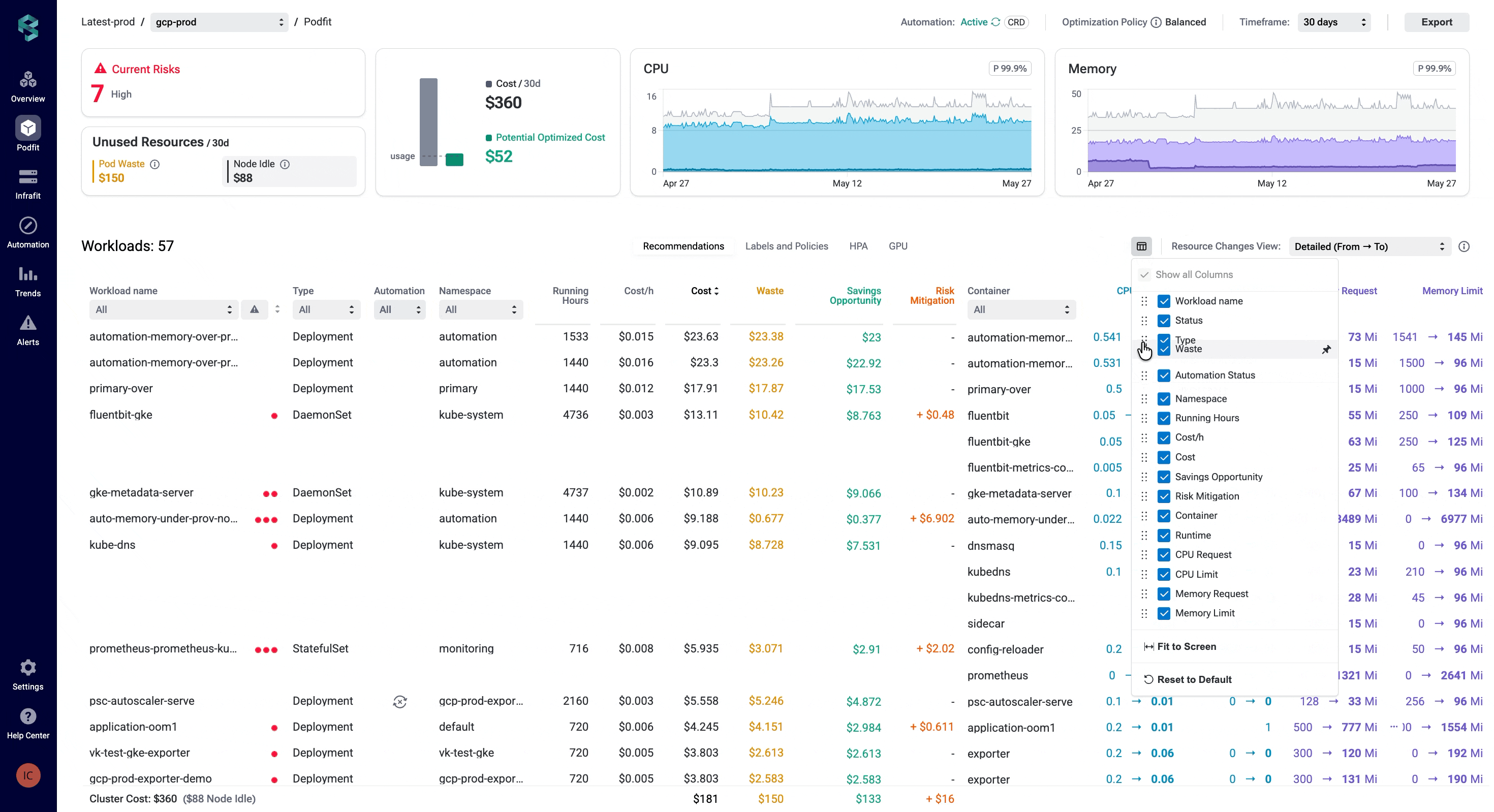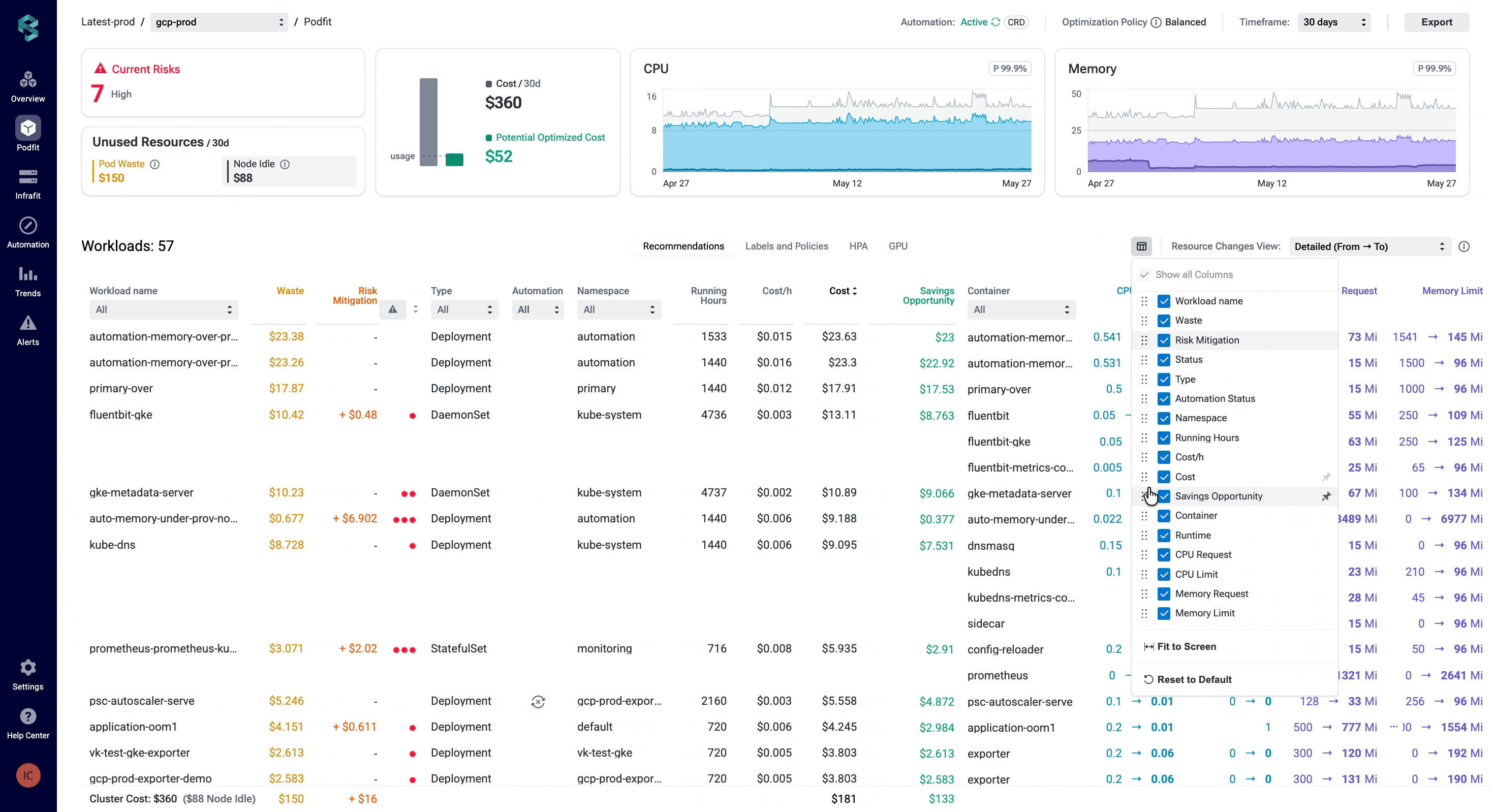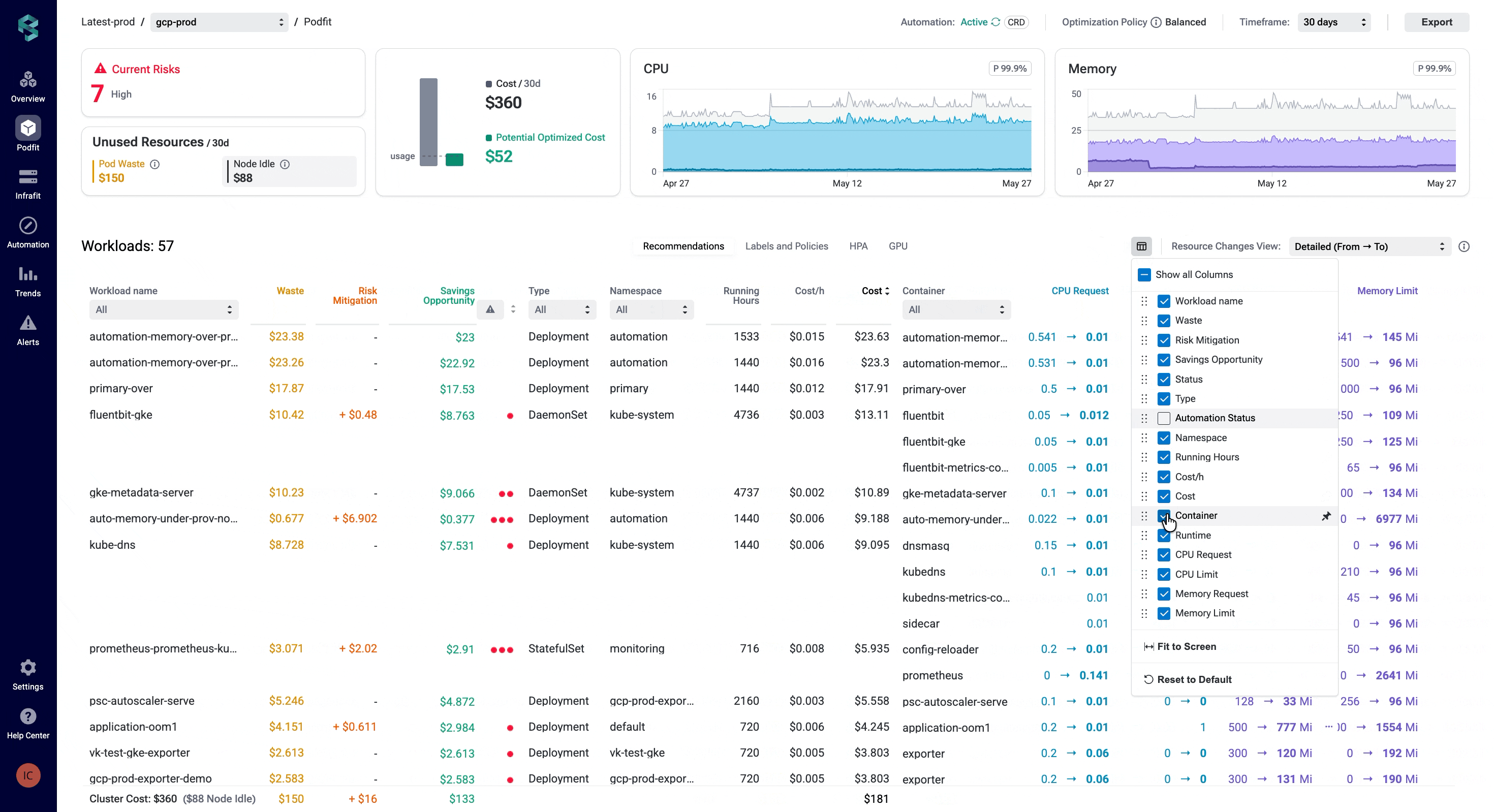
Table customization lets you take control of what to display and how. Show or hide columns, reorder them, pin the most important ones across all PerfectScale views, such as Overview, PodFit, InfraFit, Automation, and Alerts, and focus on what matters.
PerfectScale by DoiT is now ISO 27001 certified, meeting the international standard for information security management. This certification covers the controls enterprise security and procurement teams care about most: access control, data protection, incident response, and risk management. Your security team can access certification documentation directly from the Security & Compliance page to reference in procurement and compliance reviews.
This spring was all about removing frictions. We aimed to make it easier for you to see the most important, automate with confidence, improve governance at scale, and more.
...and we're continuing. Stay with us as Kubernetes optimization evolves.
Want to learn more? Visit our documentation portal or hop on a call with our team if you'd like expert assistance.
Not using PerfectScale yet? Start for free today and simplify your K8s optimization journey.


Install in minutes and instantly receive actionable intelligence.
.png)





