Subscribe to our newsletter
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.

.png)
“K8s optimization is no longer a nice-to-have but rather a requirement for production environments. The lack of proper control often leads to wasted resources, performance degradation, SLA/SLO breaches, and increased operational risk, which are not acceptable in modern cloud environments," said Amir Banet, General Manager of PerfectScale by DoiT. "This has moved Kubernetes optimization from reactive cost reduction and performance issue fixes to a continuous process that ensures efficiency, resiliency, and reliability during the development lifecycle.”
PerfectScale’s product direction stays aligned with this trend, translating actual engineering needs into execution.
If you’re involved in modern application development, you’ve probably noticed that today’s environments are no longer predictable or static, and what worked yesterday often doesn’t work today. We can highlight the key areas where these changes take place.
Cloud infrastructure is now more diverse, more dynamic, and subsequently more expensive. Teams run traditional services in a mix with GPU-based AI workloads, Java-based applications, and short-lived ephemeral jobs. Each of these components has a different nature and resource consumption patterns, so what works for basic CPU and memory management may break mixed K8s environments. On top of that, optimization requires a multi-layer approach, covering not only workload sizing, but also node-level and bin-packing efficiency.
At the same time, development and delivery sped up, encouraging teams to introduce rollout strategies, such as canary and blue-green, as well as autoscaling solutions to adapt quickly to these updates. That introduces new challenges for optimization, where the decisions should now be aligned with the delivery and scaling techniques.
Manual optimization approaches still play a role in the show. However, growing environments and infrastructure complexity make them less effective, increasing the demand for advanced autonomous optimization to optimize clusters without performance tradeoffs.
Multi-cloud environments, discounts, and specific EDP's and resellers’ contracts make it difficult to connect actual K8s spend and reflect it in optimization decisions. Without precise cost visibility, teams can't identify where to act first to address the most pressing issues, properly evaluate the impact of optimization efforts, and make meaningful, data-driven decisions.
These trends create a new reality for engineers. Teams need to adapt quickly, apply advanced multidimensional optimization techniques, and stay proactive rather than reactive. If this feels familiar, that’s completely normal! These are the conditions the teams are operating in today, and they shaped PerfectScale’s direction, turning these challenges into product execution.
The challenges teams face today are wide-ranging, and to make meaningful progress, we focused on a few key areas that shaped PerfectScale’s product direction to support engineers’ needs: optimization coverage and use-cases, enhanced automation, additional safety mechanisms, improved visibility, and expanded governance.
Still with me? Let’s take a closer look at these areas.
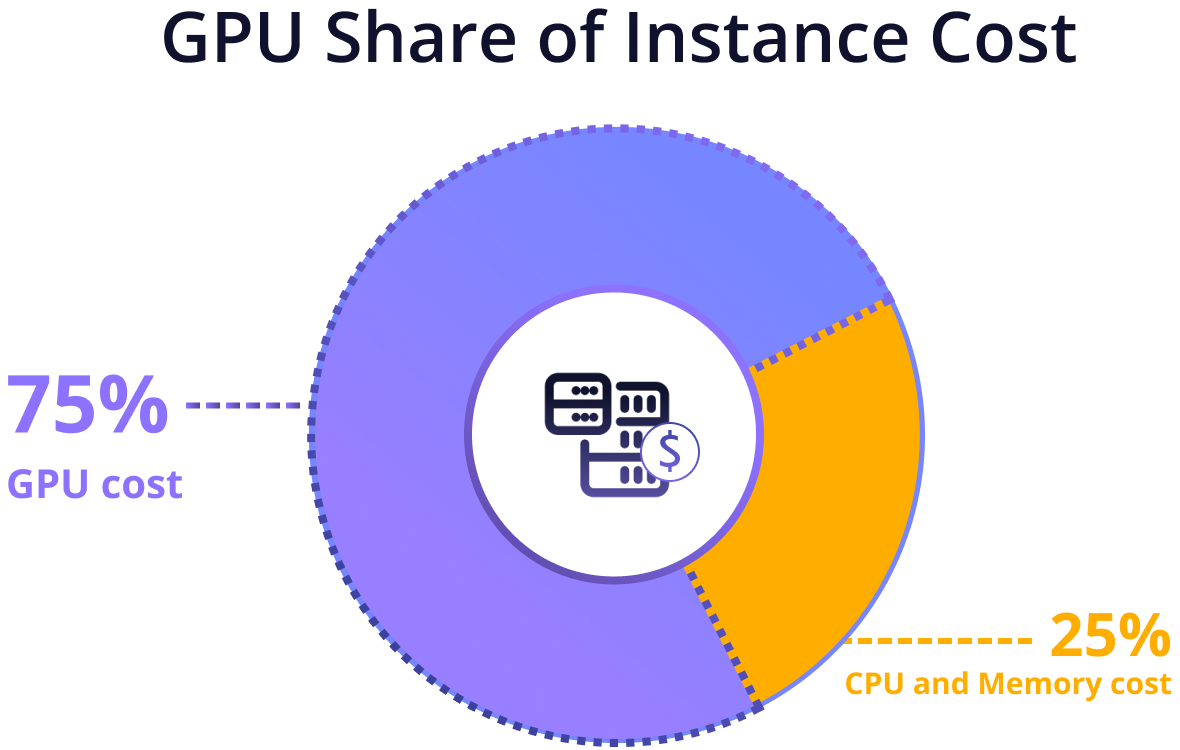
For teams running AI workloads, GPU utilization is often a blind spot. Without a clear understanding of these key metrics, managing such applications and optimizing resource allocation becomes a complicated task. Since GPUs can make up to 75% of the cost of a GPU-enabled machine, with CPU and memory taking the rest, inefficient GPU usage quickly increases the cost of those workloads. This means that even small inefficiencies on GPU nodes can lead to significant waste, as GPUs are the most expensive part of the machine. To help you spot these inefficiencies early and eliminate them before they impact your cloud bill, we released GPU visibility - a feature that collects GPU utilization metrics and translates them into clear insights, so you can precisely analyze trends over-time and take a proactive data-driven action.
Another important area that came out of our investigation is Java container optimization. In fact, Java containers differ from regular Kubernetes workloads. JVM memory management, including heap and non-heap sizing, as well as garbage collection, requires a specific, Java-tailored optimization approach, rather than standard CPU and memory tuning. This means that the teams may struggle when applying classic K8s optimization techniques to these containers, leading to wasted resources or service instability. To remove this friction between K8s and JVMs, we aligned autonomous optimization with JVM metrics, enabling teams to safely fine-tune Java workloads, prevent instability, performance degradation, and maintain an efficient and stable K8s environment.
Workload sizing is only one part of optimization. Inefficiencies can still appear at the infrastructure layer. In customer clusters just starting their optimization journey, we often see up to 60% of wasted Kubernetes spend comes from idle (unutilized) node capacity. This often happens for a few reasons: limited node-level utilization visibility, suboptimal instance types, and autoscaling that relies on manually guestimated workload size.
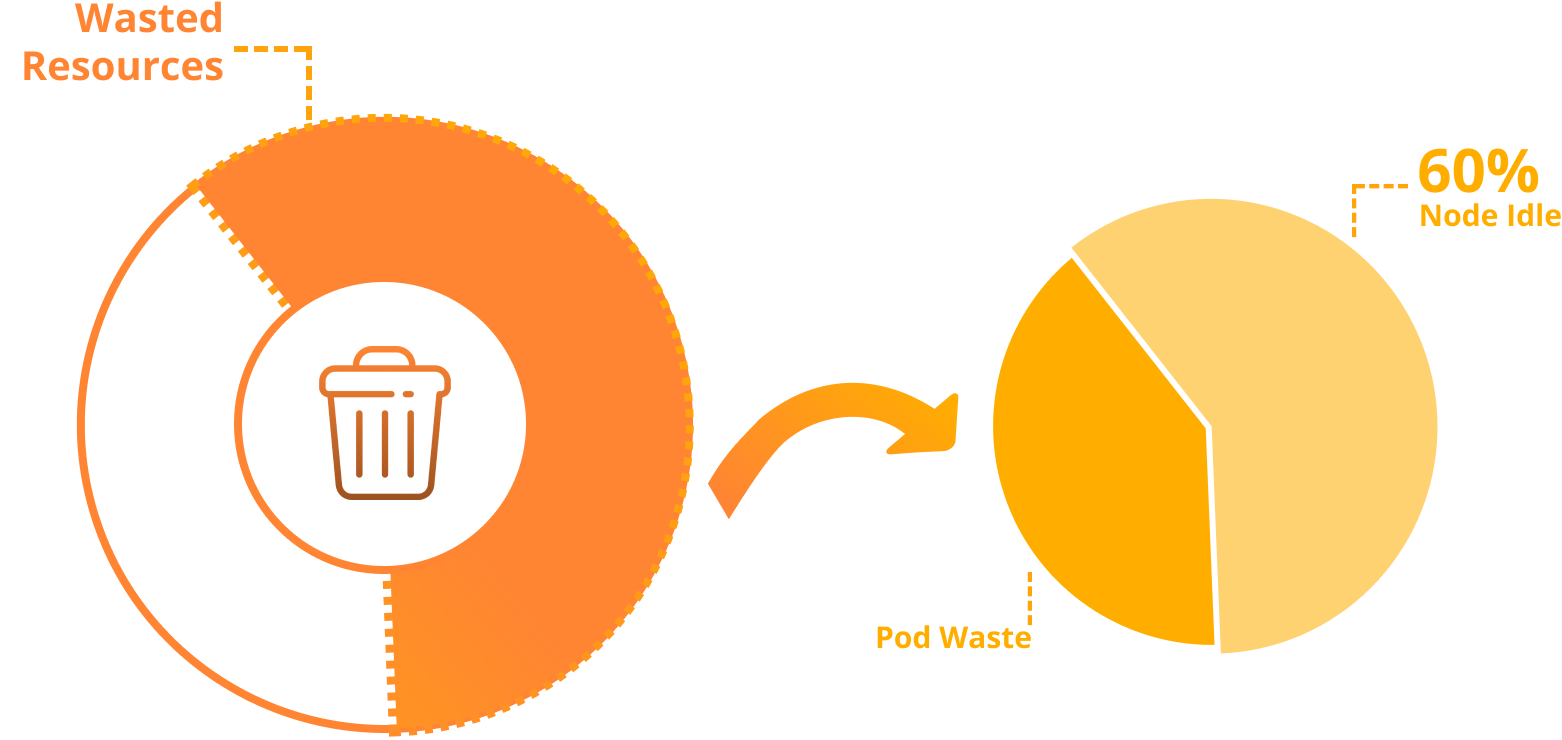
While we already know how to act with pod-level right-sizing, selecting the right nodes to support workload needs still remains an open question, especially when solutions like Karpenter are not implemented. To fill this gap, we launched node recommendations as part of PerfectScale Infrafit, providing teams with a complete solution to minimize node idle resources, making up to 50% savings.
Last but not least, data accuracy is key! When cost data is inaccurate or incomplete, you may struggle to accurately prioritize optimization efforts or measure their actual impact. This gap often occurs because of unique pricing conditions, contracted rates, and discounts, making listed prices far from reality. PerfectScale gradually addresses this friction by pulling cost data from cloud providers and taking into account contracted rates from resellers and EDPs, ensuring every optimization decision is backed by accurate cost data. Starting with AWS CUR and GCP Cloud Billing, PerfectScale now also supports seamless integrations with Azure Cost Management and can automatically pull billing data from DoiT Cloud Intelligence (DCI).
One common point of friction in autonomous optimization is that vertical scaling often requires pod restarts, creating risks of service disruption. This can put teams off from updating resources, leading to over-provisioning and wasted K8s spent. Autonomous optimization in-place addresses this issue by right-sizing workloads without restarts, making optimization smoother and reducing K8s cost without risks of downtimes. Today, we can see that more and more teams are comfortable adopting in-place optimization in production. Almost 20% of our customers are already running Kubernetes versions that support in-place workload resizing, enabling in-place automation across around 21% of clusters onboarded to PerfectScale.
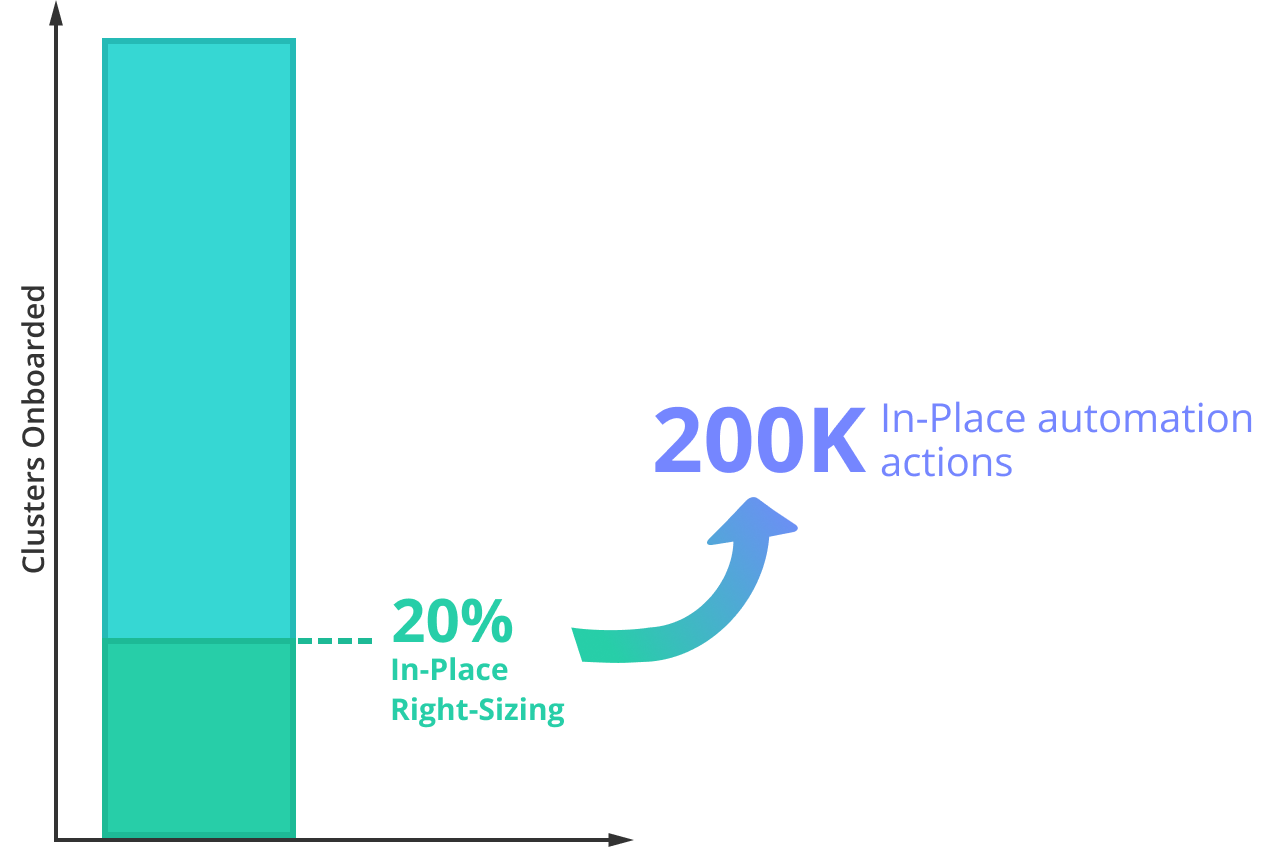
Over January 2026, PerfectScale executed up to 200K in-place automation actions to address resiliency risks early and reduce K8s waste, improving performance and saving engineering time, without restarts or manual effort.
Continuous optimization becomes even more challenging when workloads have a dynamic, short-lived nature. If you run AI/ML services on Kubernetes, you might be familiar with this. Workloads such as Spark jobs and Airflow don’t run long enough for traditional optimization approaches to analyze and tune them effectively. Inspired by this challenge, we introduced autonomous ephemeral workload optimization. It enables effortless optimization of K8s workloads, even in dynamic environments, eliminating unused capacity, reducing cloud costs, and ensuring peak performance without latency.
Safe optimization is key! Teams need to improve efficiency without introducing downtime or latency, otherwise, they may end up optimizing not just infrastructure, but also customer portfolio 😬.
If you use progressive delivery strategies such as canary or blue/green deployments, K8s optimization becomes more complex. Multiple versions often run in parallel, with imbalanced traffic distribution and different stability characteristics. We observe these patterns across ~18% of our customers who are adopting such strategies, which motivated our team to align continuous optimization with continuous delivery. Rollout-aware automation understands the full context of the implemented rollout strategy, enabling teams to deliver faster without compromising the efficiency and stability of their services.
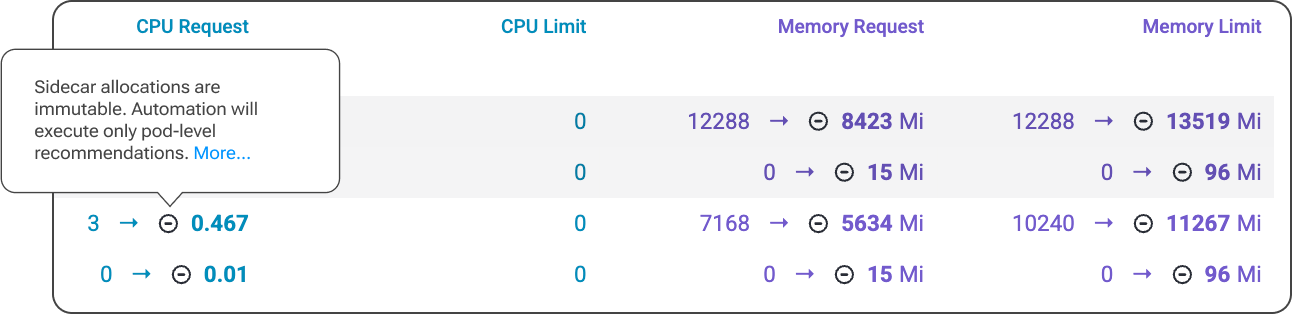
Another safety aspect appears when workloads include injected containers. These additional components have their own resource behavior, which standard optimization logic may not take into account. To prevent accidentally breaking dependency chains or resource isolation assumptions, we introduced an algorithm that automatically detects injected sidecar containers and ensures automation respects them.
How does your team make optimization decisions today? And how long does it take to validate their impact and ensure they’re correct? Quite challenging without granular, tailored visibility, right? To support confident decision-making, we expanded advanced visibility across the PerfectScale platform, providing deeper breakdowns of utilization behavior, performance risk indicators, and resource waste patterns.
The new revisions timeline enables your team to seamlessly track resource adjustments as well as the reasons behind them, helping you better understand changes in utilization or cost.
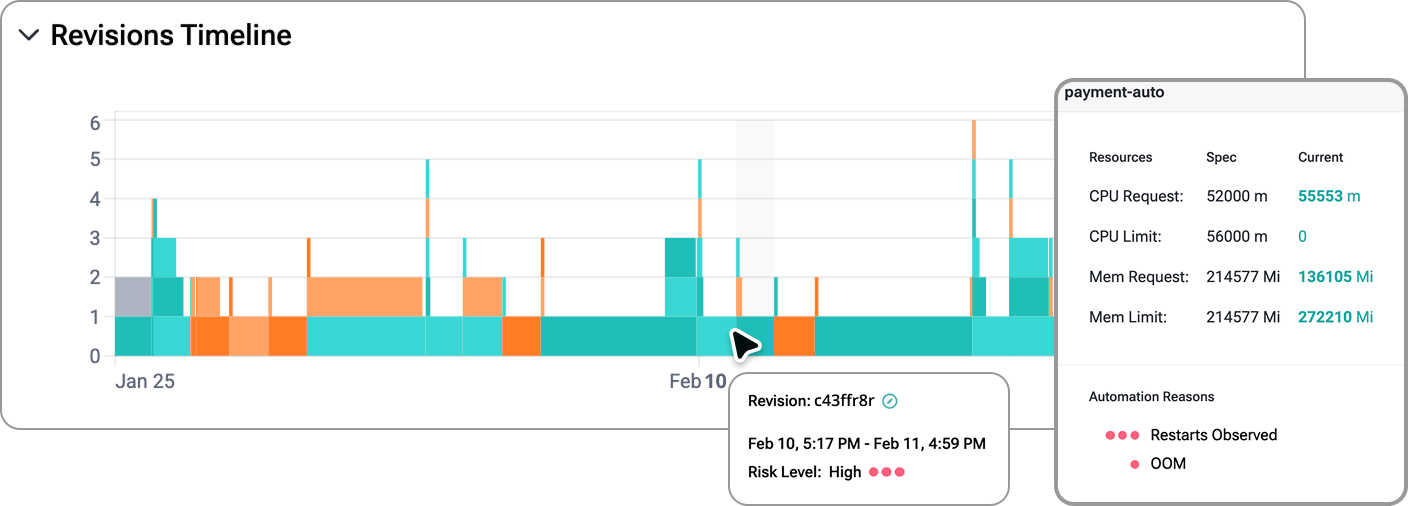
Additionally, to ensure optimization efforts keep pace as your infrastructure grows, we released the cost vs waste widget, a feature that compares overall spend against detected inefficiencies over time. On the scaling side, HPA visibility provides deep insight into horizontal autoscaling behavior, showing how workloads scale, how replica counts change, and how utilization evolves before and after scaling events.

Finally, you can now stay on top of and react quickly to cost anomalies identified in your workloads with financial alerts. We notify you when cost or waste spikes appear, ensuring you can address them early, before they affect your cloud bill.
At this point, we’ve covered the major key aspects of optimization: from workload tuning and automation to safety and visibility. The final slice of this pie is governance, the layer that gives teams granular control over optimization behavior and ensures the processes are aligned with cloud-native operating standards.
Do you run Java on Kubernetes? I know, we’ve already asked that before, but now let’s look at it from a different angle. If you do, you may notice that Java services CPU and memory are playing slightly different games.

CPUs can often be adjusted more aggressively, as the JVM can generally handle short-term throttling (if it happens), often resulting in meaningful cloud cost reduction. Memory is different. JVM workloads manage heap and non-heap memory internally, and when container limits don’t align with JVM behavior, the result can be performance degradation, latencies, or even OOMKills. That is why resource allocation policies can't be unified. PerfectScale allows teams to define independent policies for CPU and memory, ensuring recommendations and automation are aligned with cost-efficiency goals and reliability requirements. On top of that, for memory-sensitive services, teams can leverage the request=limit policy. This will guarantee memory for such workloads and eliminate OOM risks or noisy-neighbor effects.
Even with a well-configured optimization flow, unexpected resource spikes may occur. Issues such as CPU throttling or OOM may require immediate reaction, even if changes are restricted by scheduled maintenance windows. The motivation is clear, so we released a maintenance window bypass for critical events, so automation can apply protection actions instantly when they are needed.
Finally, seamless integration with existing cloud-native workflows is a must! Customization through CRDs allows you to define and manage every component of your PerfectScale optimization ecosystem directly within GitOps pipelines, from custom pricing to communication channels, ticketing systems, and more.
Until now, we mainly focused on building a comprehensive SaaS platform to help teams take full advantage of the cloud - scalability, flexibility, and quick delivery. However, strict security policies and regulations still enforce some organizations to isolate their services, including the optimization layer, within their private environments. To support these needs, we introduced a Self-hosted PerfectScale installation. This allows teams to run the platform within their own infrastructure, meeting data residency requirements, compliance constraints, or limited outbound connectivity, while leveraging the same optimization and automation capabilities.
If at least one of the challenges above resonates with you, welcome to the club. Mixed environments, fast delivery cycles, cost and resilience pressure, and production constraints are all part of the new Kubernetes reality. Shaped by real environments and the everyday trade-offs engineers face, PerfectScale removes the complexity associated with K8s optimization, making it actionable, data-driven, safe, and aligned with how teams operate today.
…and we’re continuing to learn and improve. Stay with us as Kubernetes optimization continues to move forward.
📖 Find more details and additional features in our documentation.
🦸♀️Hop on a call with our team if you’d like expert assistance.
Not using PerfectScale yet? Start for free today and simplify your K8s optimization journey.


Install in minutes and instantly receive actionable intelligence.





.jpg)


