Autonomously Boost Your K8s
Resilience and Performance
PerfectScale enhances Kubernetes performance by autonomously right-sizing workloads, preventing downtime, and optimizing resource use for 99.99% availability.
%20(1).png)
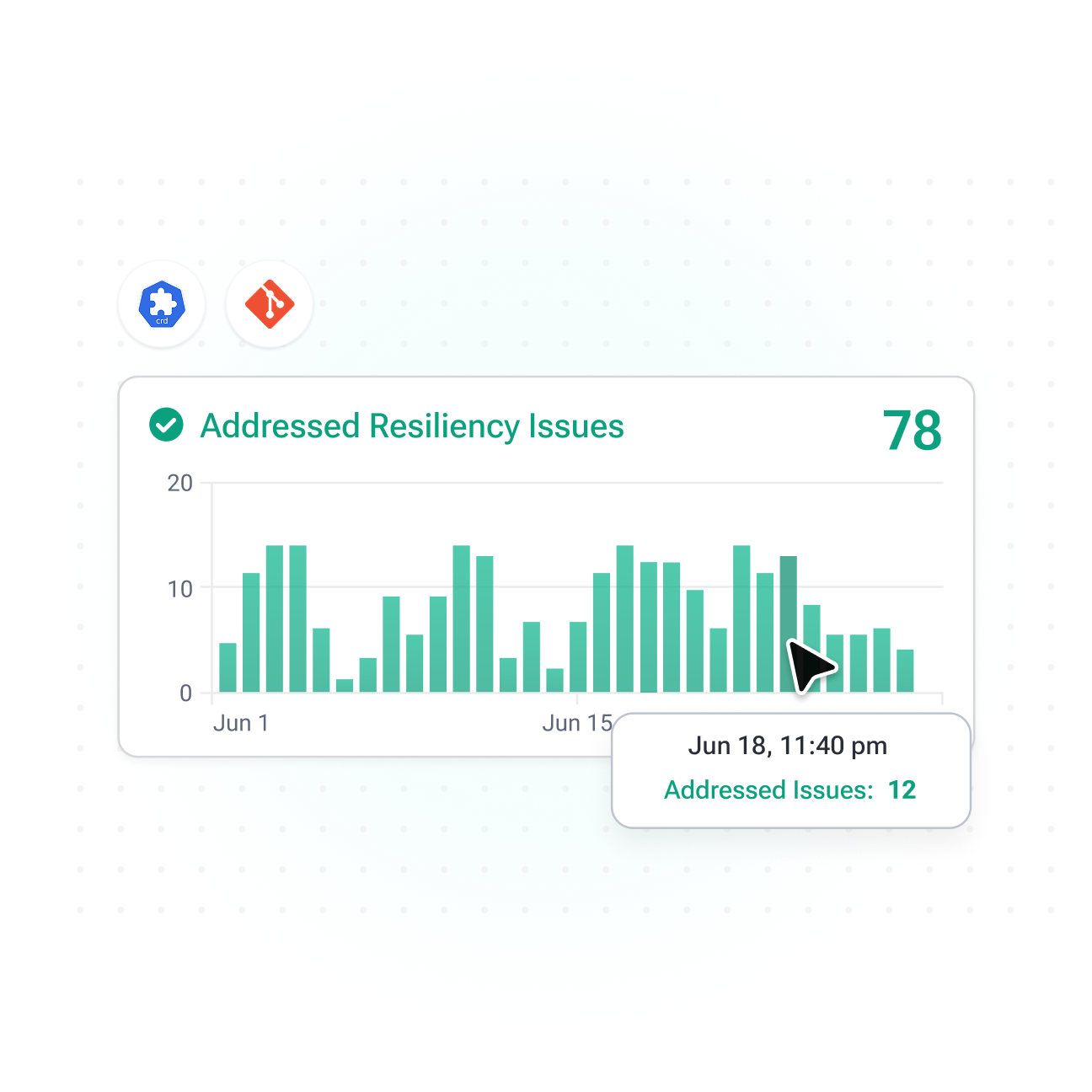
Automatic Issue Remediation
Maximize uptime and eliminate latency by instantly identifying and fixing resiliency risks to deliver consistent service excellence.
- Prevent Configuration Errors: No CPU Request, No Memory Request, No Memory Limits, etc.
- Avoid Resource Under-provisioning: OOM, CPU Throttling, Eviction, etc.
- Eliminate Code and Autoscaling Configuration Errors: Suspected Memory Leak, Hitting Max Replica, etc.
Infrastructure Hardening
Get holistic visibility across your nodes to proactively identify misconfigurations that could harm your infrastructure.
- Prevent node over-commitment: Ensure stable nodes and avoid evictions with precise memory limit recommendations.
- Ensure Proper Node Affinities and Taints: Quickly spot misconfigurations by analyzing workload scheduling patterns across node groups.
- Choose Optimal Nodes: Align resources with workload demands by choosing the most suitable node types for your pods.
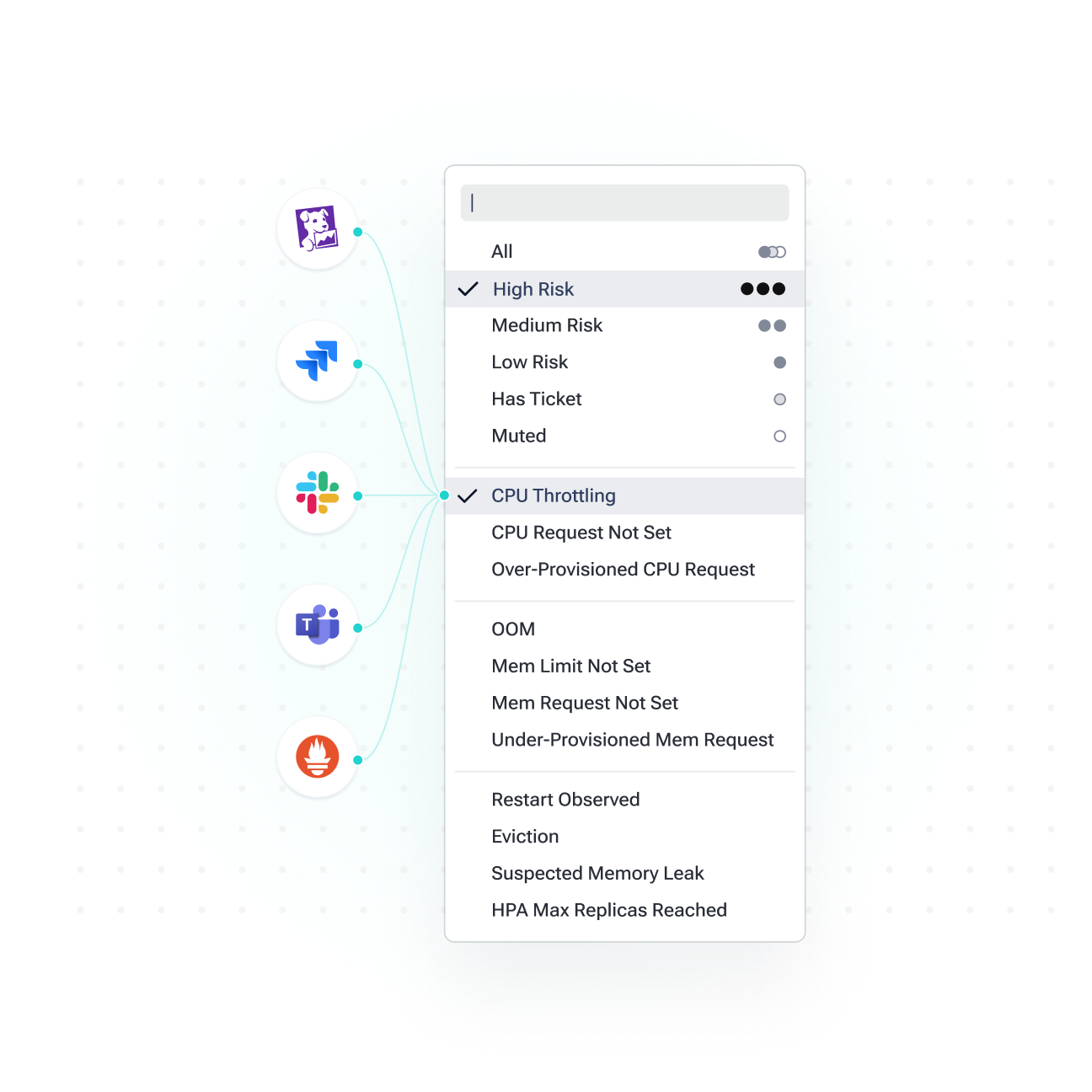
Impact-Driven Prioritization
Ensure service consistency by focusing on and resolving critical issues in real time with advanced auto-prioritization.
- Align Alerting with your SLA/SLOs: Customize alerting to keep your service within target levels.
- Receive Instant Notifications: Stay informed by connecting your preferred communication channel, like Slack, MS Teams, or DataDog Alerts.
- Escalate with Established Workflow: Ensure every issue is handled properly by creating a ticket in one click.
Feature Chart

Install in minutes and instantly receive actionable intelligence.
FAQs
Kubernetes performance indicates how reliably and resiliently clusters run workloads. It can be measured by availability, continuous uptime, and stability during regular activity and traffic spikes, ensuring applications meet their declared service levels.
To quickly and efficiently improve performance, you first need to identify the most pressing issues. By rightsizing pods and addressing risks such as high CPU throttling, memory pressure, etc., can deliver immediate results and significantly improve cluster stability.
However, performance is never “set it and forget it.” It requires continuous optimization and proactive tuning to keep clusters resilient and reliable. This is where scaling automation plays a role. By configuring horizontal, vertical, or both autoscaling, you can dynamically adjust resources based on actual demand, ensuring your clusters have sufficient resources to continuously perform.
Pod restarts, even when nodes look healthy, are a common challenge teams encounter when managing K8s clusters. In most cases, the issue is not at the node level, but on the pod. OOM, OOMKilled events, CPU throttling, memory leaks, or inaccurate requests and limits can all trigger restarts. Even with available node capacity, poor configured workloads may fail, even when the underlying infrastructure is healthy. At the same time, healthy but wrong nodes can also cause instability if they don’t fit workload requirements (for example, CPU-optimized instances running memory-intensive workloads).
PerfectScale provides a multidimensional approach for K8s optimization, enabling teams to optimize every layer of their environment, from workload right-sizing to selecting the best-fit nodes for the workloads.
Autoscaling helps keep clusters performant by adjusting resources in real time based on actual demand. When configured correctly, it maintains availability and stability during regular activity and traffic spikes. Cluster autoscalers like Karpenter scale clusters vertically by adjusting node resources based on the demands, ensuring clusters have enough resources to perform. Solutions like HPA or KEDA scale horizontally by automatically scaling the number of pod replicas, keeping resource utilization within defined thresholds and preventing underprovisioning.
PerfectScale fine-tunes configurations to ensure accurate scaling triggers, maximizing autoscaling efficiency.
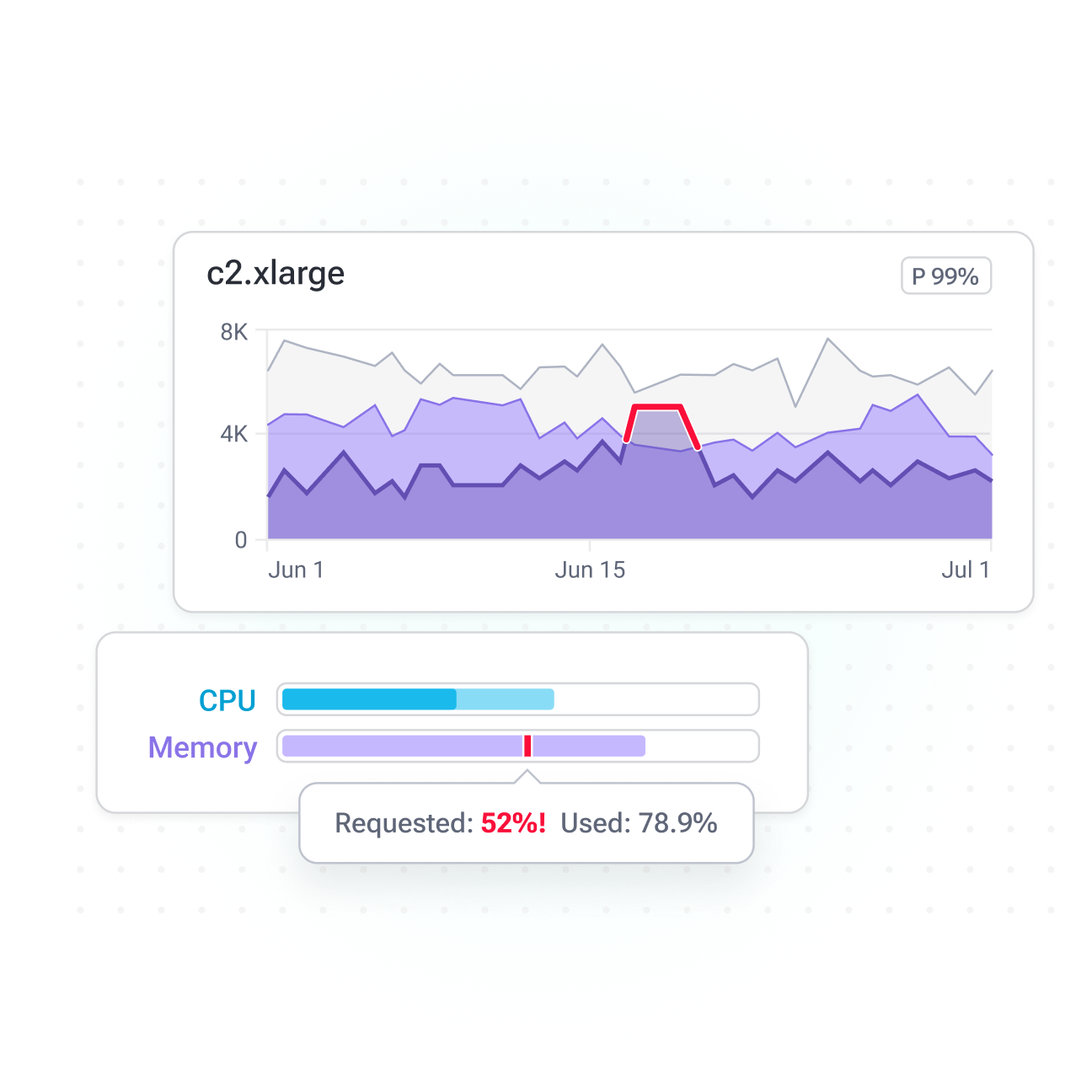
Often, teams assume that resource overprovisioning guarantees cluster stability and eliminates CPU throttling. However, adding more CPU than needed does not prevent throttling if requests and limits are misconfigured, and in some cases, it can negatively impact clusters, causing scheduling issues, leading to instability and downtime.
PerfectScale continuously analyzes K8s workloads and autonomously right-sizes CPU requests and limits based on actual demand, reducing throttling risk and maintaining peak performance while reducing cloud cost.