Subscribe to our newsletter
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.


Karpenter has become the go-to autoscaler for Kubernetes teams that care about infrastructure efficiency. It provisions nodes dynamically and gives engineering teams granular control over instance selection. For most teams running workloads at scale, Karpenter has become an integral part of the Kubernetes stack. However, getting the most value from it depends on “how well” it provisions and scales nodes.
In fact, Karpenter is only as effective as its NodePool configuration. Often, that configuration is set once during setup, based on gut feeling and general recommendations, and rarely revisited as workloads evolve. And here is the actual problem. Teams introduce new services with different CPU-to-memory profiles, usage patterns shift, workload behavior changes, and instance families that made sense a few months ago may now be costly or less available than new alternatives. All these may result in:
Many teams catch these issues too late, either when they receive a cloud bill or when production incidents, such as a spike in pending pods, happen. As a result, misconfiguration can silently burn budget or put service availability at risk.
PerfectScale now delivers actionable, data-driven recommendations for Karpenter configurations, aligned with the actual resource consumption of your workloads. By continuously evaluating your NodePool settings alongside actual workload behavior, PerfectScale helps ensure that Karpenter provides nodes that better support workload needs, improving efficiency, reducing waste, and enabling more reliable scaling.
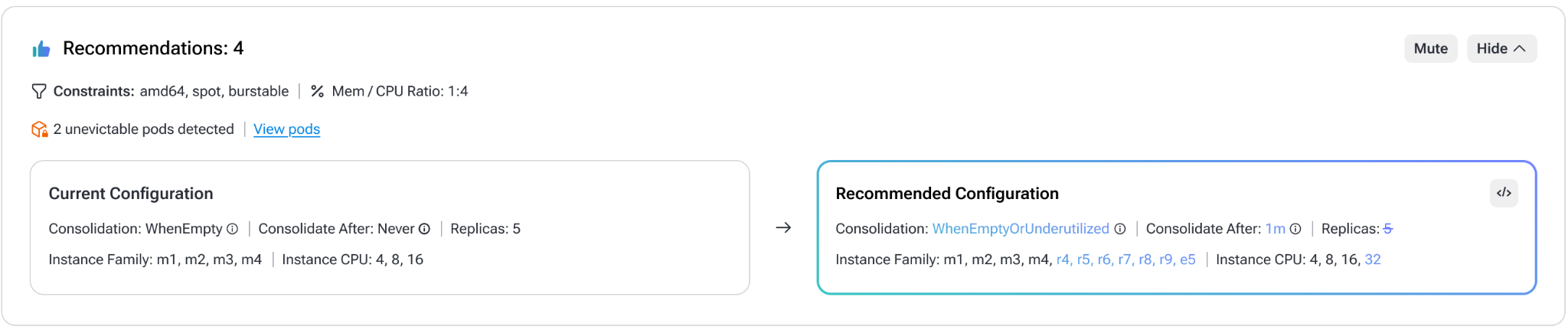
Step 1: Analyze your Karpenter configuration
PerfectScale looks at your current NodePool settings, instance requirements, consolidation policies, resource requests, and how they impact node provisioning and scaling.
Step 2: Identify configuration gaps
PerfectScale identifies when configuration is too narrow, outdated, or misaligned with workloads, including poor CPU-to-memory fit, limited instance selection, missed consolidation opportunities, and reduced resource headroom.
Step 3: Get data-driven recommendations
PerfectScale turns these insights into clear, actionable recommendations, showing where and how to improve consolidation, optimize instance category fit, adjust NodePool limits, and more.
Step 4: Unlock smarter Karpenter scaling decisions
Better configurations help Karpenter make smarter provisioning and scaling decisions, reducing infrastructure waste, improving scheduling, and minimizing the risk of capacity constraints.
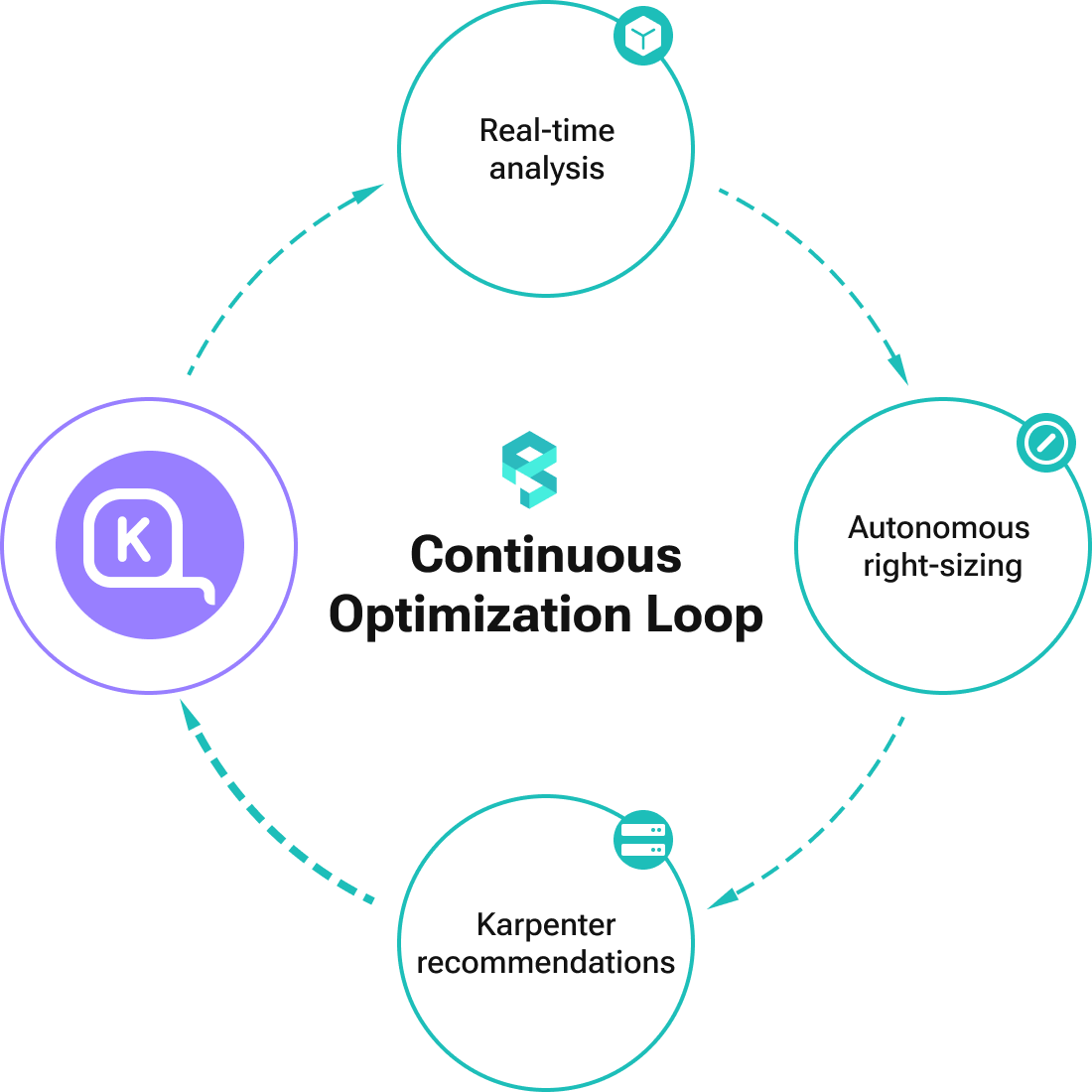
Karpenter provisions nodes based on the workload demand. When requests are over/under-provisione, or no longer aligned with actual usage, node scaling decisions are based on inaccurate signals.
PerfectScale connects autonomous workload right-sizing and Karpenter configuration optimization into a single continuous loop. It continuously analyzes workload behavior in real-time, autonomously aligns resource requests with actual utilization, and then uses the optimized input to provide accurate Karpenter recommendations, helping Karpenter make smarter scaling decisions based on how applications run today.
Karpenter Optimization Recommendations are now available in PerfectScale.
📖 Check out our docs to learn more.
Not using PerfectScale yet? Try it for free today and see it in action.


Install in minutes and instantly receive actionable intelligence.





.png)

