Subscribe to our newsletter
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.


With Kubernetes, you can scale your applications, but when you run things at scale, you get exposed to some Kubernetes reliability risks that you should be aware of.
Sometimes, a small mistake or a misstep in the resource configurations, scheduling, or monitoring can lead to downtime and poor performance.
This article will look at the top 10 Kubernetes reliability risks.
Let's dig in!
Kubernetes reliability risks refer to anything that can cause your Kubernetes applications or cluster to become unreliable, slow, or fail. They are misconfigurations, omissions or malpractices that lead to poor performance and downtime.
The top ten Kubernetes reliability risks in a Kubernetes environment are as follows:
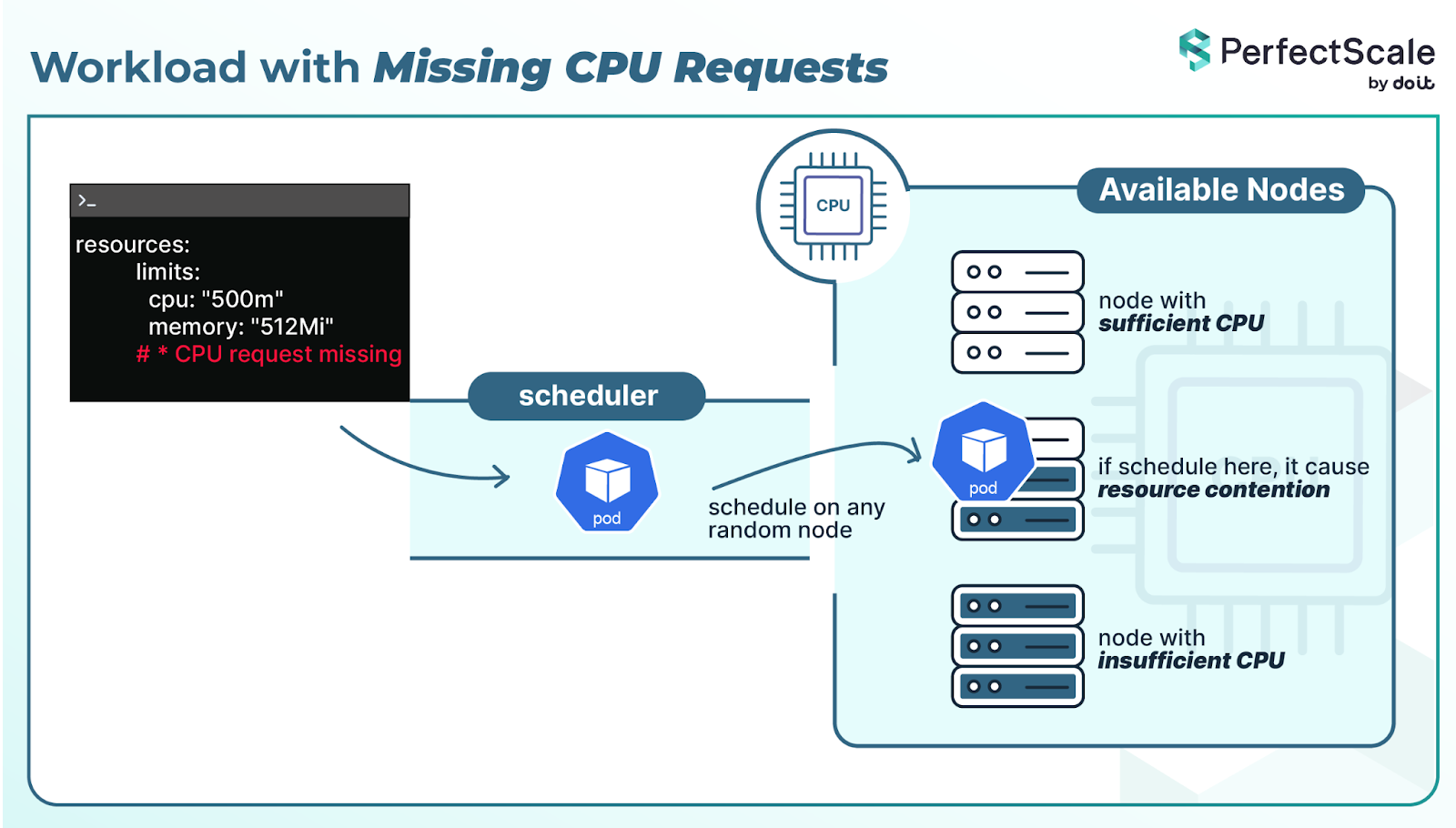
If pods execute without CPU requests, Kubernetes does not know how much compute resources they require. The scheduler may place them on any node, even if that node is already under heavy load. Visually, that seems fine, but in practice, it is not.
The issue is resource contention. When there isn't guaranteed CPU, workloads compete with noisy neighbors and can be starved of compute cycles. Pods without CPU or memory requests fall under the BestEffort Quality of Service(QoS) class, which means they have no guaranteed resources.
At scale, these issues increase. Nodes look like they have free capacity, but workloads suffer because resources are not reserved properly.
This results in slower response times, inconsistent performance, and services behaving unpredictably.
If pods might not have set memory requests, Kubernetes does not guarantee how much RAM is actually required by the pods. The scheduler may place these on nodes that appear to be available but do not have enough actual memory to support the workloads running on their nodes.
This situation becomes further problematic when multiple pods with no requests share a node. With no baseline reservations, memory can quickly become overcommitted- another key Kubernetes reliability risk. Once pressure builds, the kernel's out of memory (OOM) killer will kill the pods. This means critical applications crash and go into a restarting loop, and reliability is impacted.


If a pod has no memory limits, it can take as much memory as it wants. If an application has a memory leak, it can consume the entire node’s memory without warning. This is a severe major reliability risk.
Once the node runs out of memory, the kernel’s OOM (Out of Memory) killer decides which pods to terminate. But these decisions don’t always match business priorities; sometimes, it kill critical system pods or multiple important workloads at once, resulting in sudden outages.

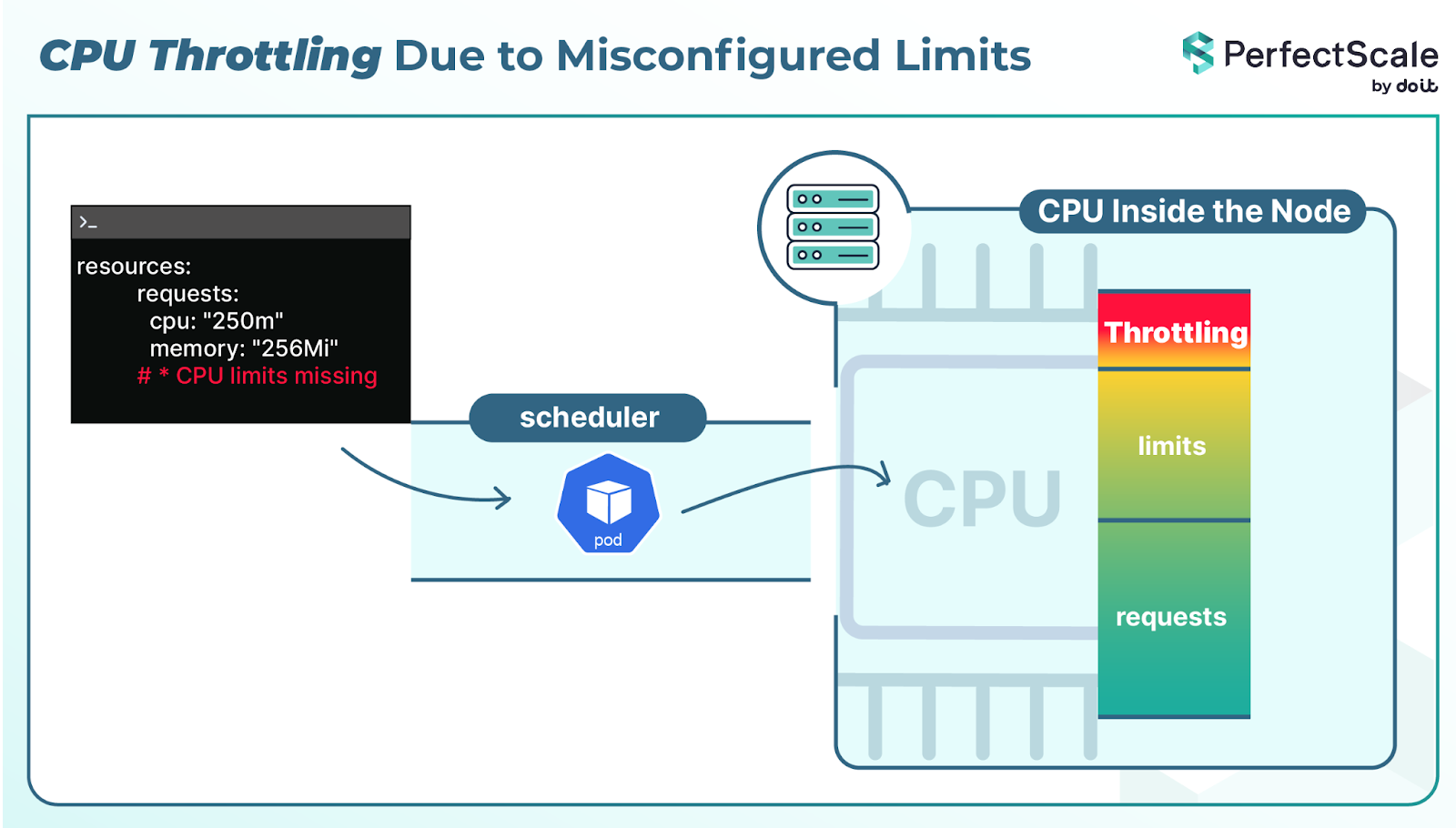
CPU limits determine how much CPU a pod can use. Kubernetes enforces CPU limits using the CFS (Completely Fair Scheduler) quota mechanism, which can throttle containers even when they aren’t actually hitting the limit.
Pods under load can become slow due to throttling. A request that normally takes milliseconds, can take seconds, which, for APIs, feels the same as downtime. You know, from a user perspective, the service is broken, even though the pod is still technically running.
Because of this, the best practice to prevent this Kubernetes reliability risk is to avoid setting CPU limits altogether and instead rely on the kernel’s CFS scheduling to fairly share CPU across containers. The key is to size CPU requests correctly while leaving limits unset for consistent performance.

This risk is realized when you set CPU or memory requests lower than what a workload actually requires. Kubernetes makes scheduling decisions based on those requests. If the request is lower and the scheduler thinks the pod is "cheap," it could place more pods on a node than it can handle- one of the top Kubernetes reliability risks. Then, during runtime, your service is fighting against other pods for available resources.
For CPU, this shows up as contention, pods waiting in the run queue, sudden spikes in latency, and inconsistent throughput. For memory, the impact is stronger: memory usage exceeds the node's headroom, and the pods could get evicted or killed by the OOM process of the kernel.

In Kubernetes memory is a hard limit, unlike CPU. If a container attempts to exceed its memory limit, Linux kills the process with an out-of-memory (OOM) error.
The Kubernetes reliability risk comes when you set memory limits too low. Many applications use more memory at certain times; for example, during garbage collection, caching, or sudden traffic spikes. If the limit doesn’t match real usage, the container keeps getting killed and restarted, ending up in CrashLoopBackOff.
A container may restart when it fails health checks, crashes due to misconfigured volumes, or hits an application error.
While Kubernetes automatically restarts failed containers (depending upon restartPolicy), constant restarts are not a risk by themselves, but it is a sign of deeper reliability issue.
The impact is big. Each restart breaks availability: requests in flight are lost, user sessions may be disrupted, and user-facing dependent services may behave in unexpected ways. At the same time, the pod looks like it’s running, but it is stuck in crashing and recovering in a loop.
The continual restarts also consume scheduling cycles, will reload their images each time, and consume CPU/memory. If multiple pods keep restarting, the extra churn can skew autoscaling, slow down other workloads, and reduce overall cluster stability.

Out-of-Memory (OOM) events occur when a container in a pod uses more memory than the node can provide or what has been allocated. That’s a common Kubernetes reliability risk. At that point, the Linux kernel’s OOM killer steps in and forcefully terminates the container to free up resources. OOM events are risky because they usually hit without warning and immediately disrupt the workload.
The danger of OOM events is that they don’t just affect the failing pod; but can also affect the entire system.
Events:
Type Reason Age From
Message ---- ------ ---- ---- -------
Warning OOMKilled 1m kubelet
Container test-container in pod test-pod was killed due to out of memory


When the available memory, disk space, or number of processes on a node becomes low, the kubelet causes pressure conditions such as MemoryPressure or DiskPressure and starts evicting pods in order to preserve the node.
While this keeps the node healthy, it disrupts workloads that are running- very serious Kubernetes reliability risks. Over time, the constant evictions lead to unstable services, and compute is wasted due to constant scheduling.

A substantial risk of reliability within Kubernetes occurs in scenarios where there is a lack of visibility or proactive detection of issues across the cluster. If you do not know what is happening inside your system, you will not act until a failure has escalated into an outage, which directly affects users. Kubernetes itself is very dynamic with pods constantly being created, destroyed, and rescheduled. If your teams are only reacting after something fails, you have already lost the opportunity to catch early warning.

With PerfectScale, teams don’t just discover issues when it’s too late, they gain real-time visibility into 30+ critical reliability, performance, and cost errors across their Kubernetes environments. The platform not only highlights these misconfigurations and inefficiencies but also provides actionable, prioritized remediation steps. This means you can move from firefighting to proactively ensuring stability, efficiency, and cost control, keeping your clusters always in the Perfect state. Book a Demo today and start a Free Trial today!


Install in minutes and instantly receive actionable intelligence.





.jpg)


