Subscribe to our newsletter
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.


Hello, welcome everyone, in this article, you’ll learn what Kubernetes Cost reduction is, factors influencing it, and how you can cut Kubernetes costs in 5 steps.
Without fancy intros, let’s dig in!
Kubernetes cost reduction means making smart decisions about how your applications run inside clusters, like scaling, provisioning, and storing data, so that you're not spending more on compute, storage, or network resources than necessary. It’s about squeezing out inefficiencies from deployment configurations, workload sizing, and infrastructure choices, all without sacrificing performance or reliability.
Kubernetes costs can spiral out of control if not managed properly. Let’s discuss the key factors:
Kubernetes cost reduction starts with avoiding overprovisioning and poor scaling habits. Many organizations default to allocating more CPU and memory than workloads actually need, simply to avoid performance issues, resulting in underutilized resources and inflated bills. Also, misaligned autoscalers and static node groups often leave clusters running at half their capacity, yet still charging full price. Additionally, engineers may unintentionally select expensive instance types, fail to release idle volumes or load balancers, or leave non-production environments running 24/7, all of which silently inflate monthly cloud spend.
A key to Kubernetes cost reduction is maintaining the fine balance between cost and performance. Kubernetes makes it easy to scale applications for peak traffic, but without tuning, this often leads to waste. When teams don’t set appropriate resource requests and limits or fail to analyze usage patterns, they either overprovision to play it safe or underprovision and risk throttling and pod evictions. The developers frequently guess resource values, leading to “just in case” provisioning that adds no real benefit. Also, being too aggressive with optimization can affect latency, throughput, and customer experience. The cost-performance tradeoff must be calculated and regularly revisited, not left to intuition.
Finally, the sustainable Kubernetes cost reduction depends heavily on organizational discipline and FinOps maturity. Without cross-team visibility and accountability, cloud bills remain a backend problem. The cost should be a shared metric across DevOps, Finance, and Engineering, not just a concern for platform teams. When developers don’t see the financial impact of their design or deployment decisions, there's little incentive to change. That’s why mature teams implement namespace-level cost reports, enforce limits through policies, and build optimization into their deployment pipelines. Without a cultural shift toward FinOps, cost reduction becomes a one-time effort instead of a sustainable process.
Focusing on these points, you can significantly cut your costs in your Kubernetes environment.
To start slashing Kubernetes costs, the first step is gaining deep, continuous cost visibility because you can’t control what you can’t see. Kubernetes expenses aren't confined to individual pods; they creep into nodes, persistent storage, network traffic, and even managed control-plane services. When billing is only visible at a high-level cluster view, overspending often goes unnoticed, whether it's idle pods, oversized nodes, orphaned volumes, or unexpected egress charges.
The problem: Traditional cloud bills don’t show which workloads, namespaces, or teams are responsible for the charges. Because of this lack of clarity, hidden costs like unused workloads or high network usage can grow without anyone noticing until it’s too late.
The solution: Use Kubernetes-native cost-monitoring tools that tag resources by namespace, app, or team. These tools track usage across CPU, memory, storage, and egress in real time, provide alerts on sudden cost spikes, and let you break down costs by workload. With these insights, you can spot idle volumes, overprovisioned pods, and unusual traffic patterns quickly.
With this level of visibility, teams can detect and eliminate waste before it balloons. Cost becomes a meaningful metric - visible, trackable, and manageable. Budget alerts prevent surprises, and tagging aligns accountability across teams. It means cost visibility brings cost control, and that's the foundation for effective Kubernetes optimization.
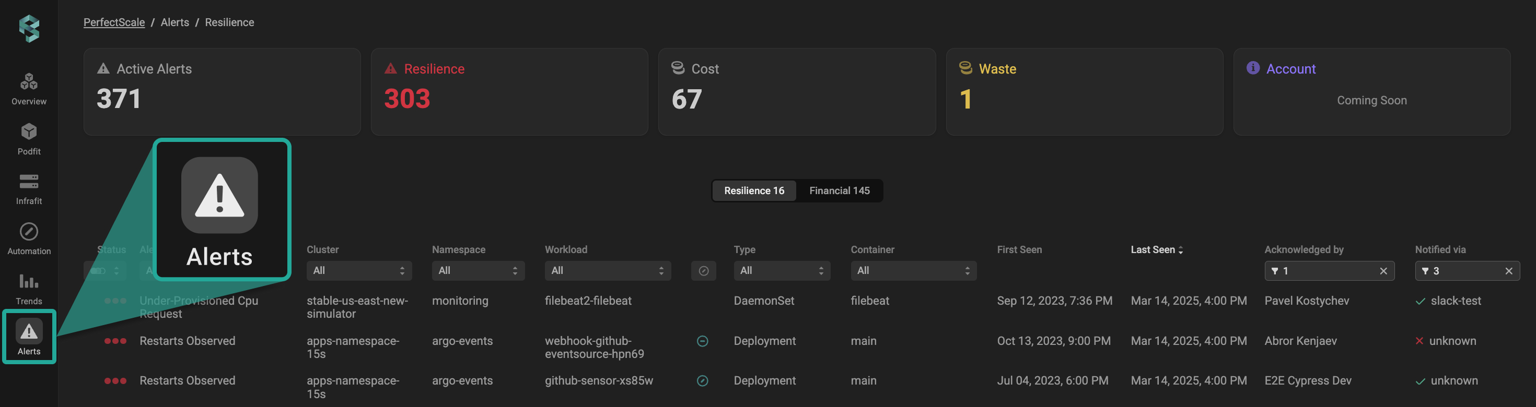
PerfectScale delivers real-time, cluster-wide cost visibility by integrating resource usage (CPU, memory) with your actual billing data.
It provides granular insights at the pod and deployment level, allowing you to view cost by namespace, workload, or team context. You can also set up real-time alerts to catch unexpected spending spikes, enabling instant identification of waste and proactive cost control.
After identifying where most of your cloud spend is going, the next step is to eliminate waste from over‑provisioned workloads. It’s all too common for teams to allocate extra CPU or memory “just in case” an app spikes. Almost half of the pods use less than a third of their allocated resources, meaning a lot of money gets wasted on idle capacity. Over‑allocation doesn’t just affect pods; it fragments nodes too, leaving empty gaps that prevent efficient packing. On the other side, under‑allocating resources leads to throttling, evictions, and poor performance.
The solution is rightsizing: use actual telemetry looking at CPU peaks, memory usage, and throttling events to adjust resource requests, limits, and QoS settings. That means tuning pods so they get exactly what they need: not too much, not too little. Then shift focus to nodes, bin‑pack pods efficiently, select the right VM sizes, and resize node pools based on actual demand. It’s essential to include storage, as unused persistent volumes often sit forgotten and continue billing even when empty.

The outcome is clear: less idle compute, better node utilization, and reduced storage waste. Rightsizing not only lowers costs but also stabilizes performance, apps stay responsive, nodes run efficiently, and infrastructure matches actual needs. It’s the kind of optimization that pays for itself and then some.
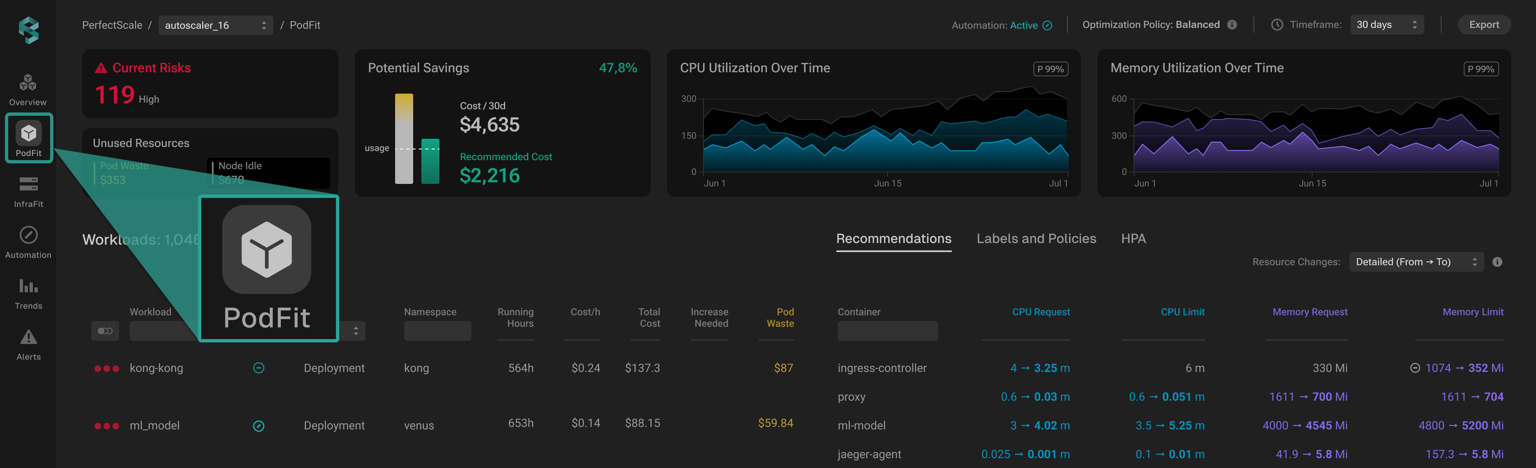
PerfectScale’s Podfit and Infrafit features analyze real-time telemetry (CPU, memory, pods, and nodes) and match it with historical usage trends.
The platform provides data-driven recommendations for setting requests, limits, and node configurations, ensuring pods and nodes are right-sized, with no guesswork. PerfectScale also continuously measures waste and underutilization, guiding you to balance performance with cost efficiency.
When you stick with a fixed cluster size, it wastes budget in your cloud environment, either underserves your apps, or drains your wallet during quiet periods. Kubernetes provides three autoscaling tools to bridge this gap: Horizontal Pod Autoscaler (HPA), Vertical Pod Autoscaler (VPA), and the Cluster Autoscaler. HPA adjusts the number of pod replicas based on metrics like CPU or memory, while VPA tweaks each pod’s resource limits; Cluster Autoscaler scales node counts based on pending workloads .
However, setting these up incorrectly can cause trouble. For example, if both HPA and VPA react to the same metric, you may find pods spinning up and down constantly, which feels like a ping-pong effect, leading to instability and unnecessary cost . Similarly, autoscalers can misfire without proper cooldown periods, causing clusters to thrash in response to short-lived spikes .
The fix is tuning. Start by adjusting HPA thresholds and cooldown more conservatively, use a buffer between scale‑up and scale‑down triggers, increase polling intervals, and smooth out rapid spikes with longer averaging windows . When combining HPA and VPA, ensure they act on different metrics, for example, let HPA scale for CPU while VPA optimizes memory allocation, so they don’t work against each other.
For node-level scaling, enable Cluster Autoscaler (or alternatives) to add and remove nodes automatically, preventing idle compute when demand drops. Consider maintaining a buffer of pre-warmed nodes to reduce latency during scale-up. Whenever scaling triggers, ensure appropriate grace periods and pod disruption budgets are in place so workloads don't abruptly fail during node removal.
This balanced autoscaling strategy properly tunes HPA, VPA, and Cluster Autoscaler that ensures your cluster scales smoothly in response to real demand, avoids resource thrashing, and helps you pay for only what you need.
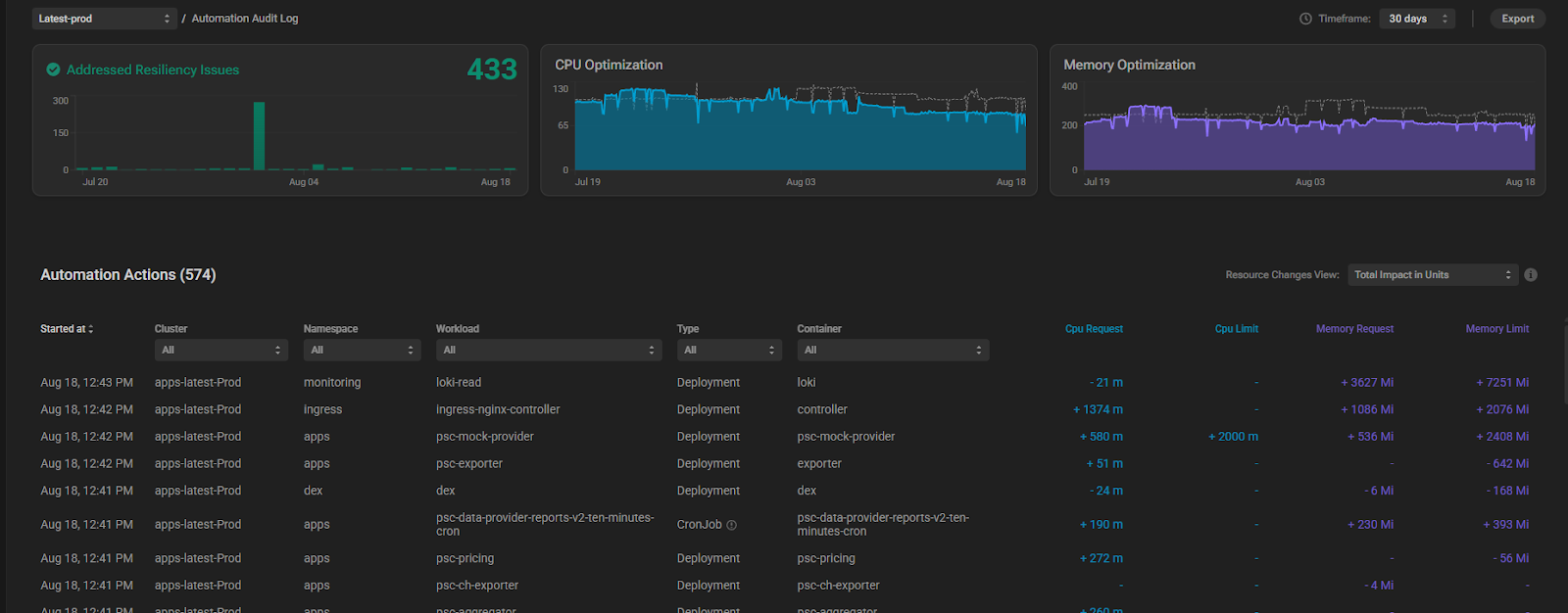
PerfectScale comes in as a smarter, safer alternative to VPA that provides continuous rightsizing without the instability. PerfectScale’s Automation intelligently and continuously tunes CPU and memory allocations for your workloads without manual effort.
It safeguards performance by immediately increasing resources when needed and reduces waste gradually to optimize cost, all while respecting configurable policies and guardrails. Automation can be applied at the cluster, namespace, or workload level to align with your operational strategy.
When you use on-demand instances, you pay more money than necessary. You can significantly cut cloud costs by moving flexible, fault-tolerant workloads (such as CI jobs, batch processing, logging, or ETL tasks) onto spot or preemptible instances, which often cost 70–90% less than on-demand pricing. The trade-off is interruptions; cloud providers can reclaim these instances with little warning, so they’re best suited for workloads that can easily restart or tolerate disruption. At the same time, you can reserve capacity for stable, always-on workloads through Reserved Instances or Savings Plans, locking in 40–70% discounted rates for a 1–3 year commitment.
The problem lies in coordination: you need to balance the unpredictability of spot instances against the reliability of reserved capacity. If you pick the wrong mix, you can face too many interrupts or idle reserved instances, and you can end up paying more than you save. Managing this manually across large clusters becomes overwhelming.
The solution is a smart, automated strategy that blends spot, reserved, and on-demand instances based on current demand and workload criticality. This approach ensures workloads fall back to on-demand or reserved capacity if spots disappear. Predictive orchestration, such as prioritizing spot instances with lower interruption risk and maintaining a small buffer of reserved nodes, keeps performance steady and costs optimized.
With this, you slash compute costs by up to 90% on transient tasks, secure stability for essential services at much lower rates, and eliminate wasted spend entirely.
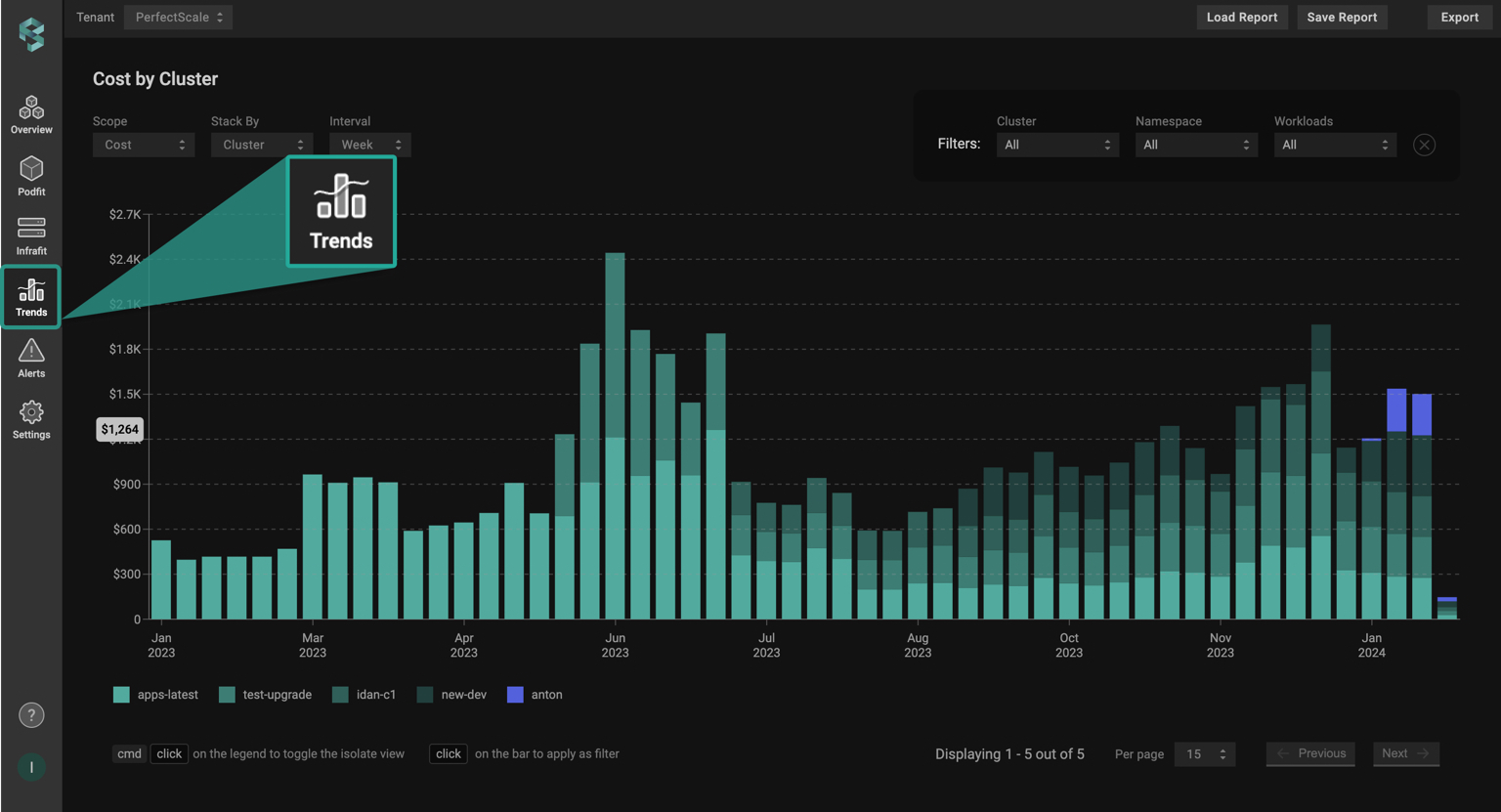
PerfectScale’s Trends Monitoring feature tracks cost patterns and seasonality in your Kubernetes environment over time.
You can customize views by workload, namespace, or node group and select time intervals (hourly, daily, weekly, monthly) to observe recurring spending peaks and lulls. By this visibility get a clear understanding of your optimization progress, which components of your environment are well-optimized, and what requires attention.
Combined with billing integration (via AWS CUR, Azure Cost Management, or GCP Billing), these insights help PerfectScale recommend the most effective mix of on-demand, reserved, and spot instances to balance cost-saving with performance reliability.
A large chunk of Kubernetes costs stems from idle infrastructure, unused test clusters, forgotten PersistentVolumes, idle load balancers, and abandoned namespaces that quietly accumulate charges each month. Manually hunting these down is tedious and error-prone, but automation can make a massive difference. Simple scheduling scripts can shut down development clusters during off hours, and cleanup tools (like kube-janitor or custom hooks) can sweep out orphaned storage and services on a scheduled basis. This step alone can recover meaningful savings with minimal effort.
However, effective cost management isn’t just about technical cleanup; it’s a people challenge too. That’s where FinOps comes in: you need regular reviews of expenses (weekly or monthly), developer-friendly cost dashboards, namespace-level chargeback, and CI/CD integration of cost metrics. When developers see real-time cost feedback, for example, “this deployment added $X/day to your namespace,” they naturally start optimizing. Building this awareness turns cost efficiency from a one-off cleanup into a sustainable culture of accountability.
PerfectScale helps you keep your Kubernetes setup clean and efficient by highlighting idle nodes and unused workloads.
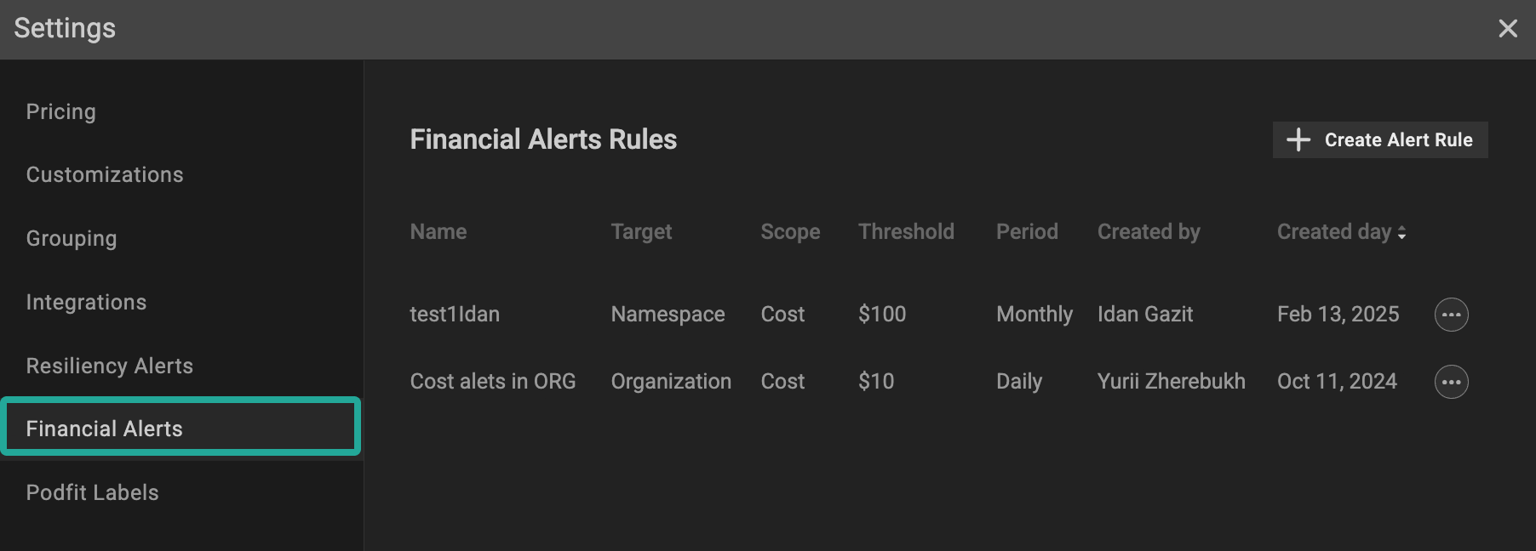
Those silent budget-eaters hiding in your environment. It also provides Financial Alerts, configured to notify you immediately when cost or waste thresholds are crossed, so you can act fast before small issues become big bills.
Book a Demo today and Start a Free Trial today with PerfectScale!


Install in minutes and instantly receive actionable intelligence.








