Subscribe to our newsletter
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.


Kubernetes errors are one of the most common challenges developers face while running workloads in production, resulting in failed deployments, downtime, and wasted time troubleshooting.
In this article, we’ll discuss the top errors and how to fix them, which can save you hours of frustration and keep your clusters healthy.
Let’s dig in!
CrashLoopBackOff means that a Kubernetes pod is repeatedly starting and crashing. Kubernetes retries according to its default restartPolicy and uses exponential backoff, first 10s, then 20s, then 40s, up to a 5-minute max, to reduce resource thrashing.
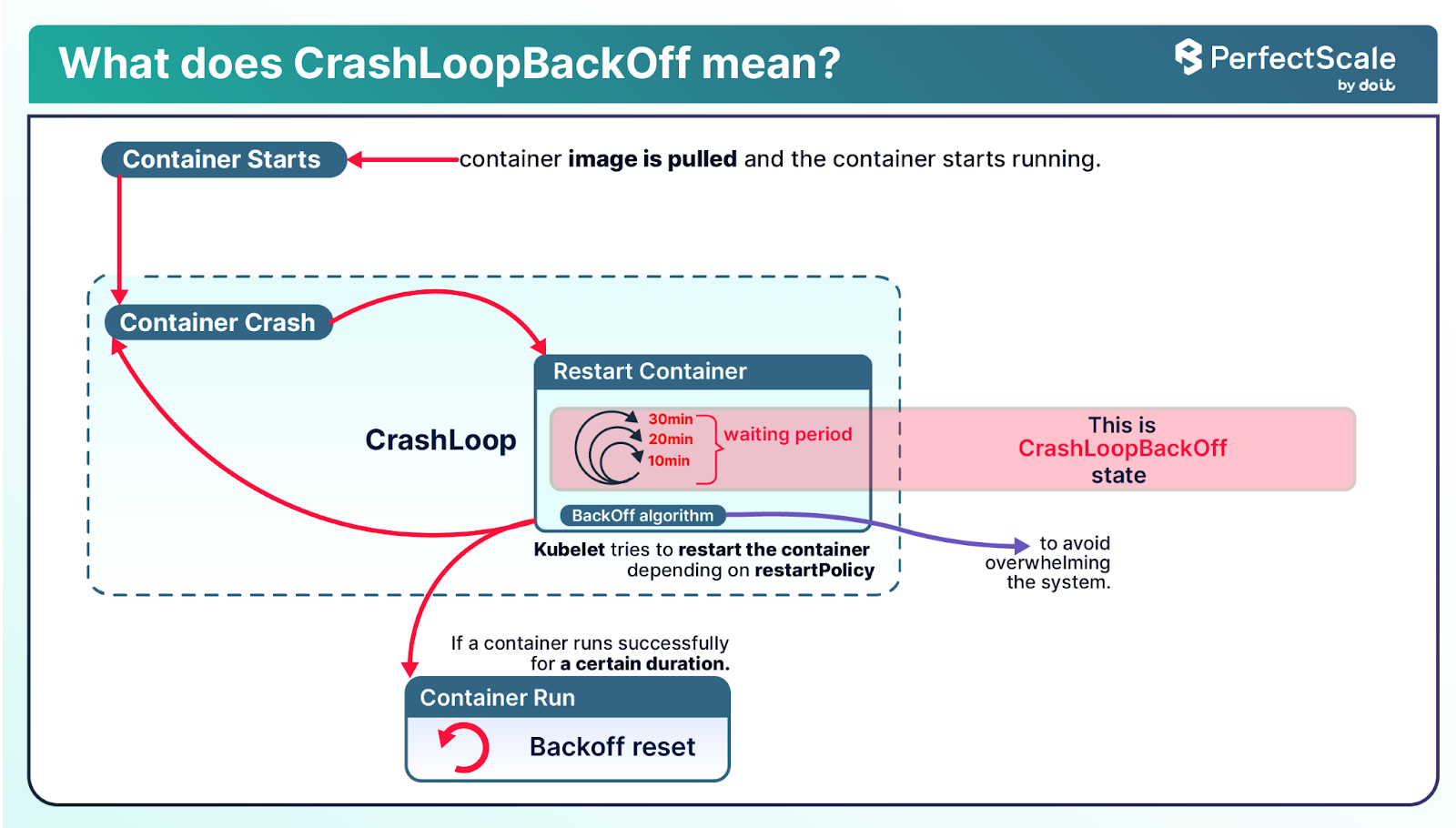
The reasons behind this:
apiVersion: v1
kind: Pod
metadata:
name: crash-demo
spec:
containers:
- name: crash-demo
image: busybox
command: ["wrongcommand"]
restartPolicy: AlwaysThis fails immediately due to a non-existing command, gives CrashLoopBackOff.
Note: Since the restartPolicy is set to Always, Kubernetes keeps restarting the container, resulting in crash loop.
a. The steps you can follow to troubleshoot the CrashLoopBackOff error:
1. Discover affected pods
kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-579667dbc7d-lll6q 0/1 CrashLoopBackOff 6 2mLook for pods in CrashLoopBackOff with a high restart count.
2. Inspect pod details & events
kubectl describe pod <pod> -n <ns>
State: Waiting
Reason: CrashLoopBackOff
Last State: Terminated
Reason: Error
Focus on “Last State”, “Reason: Error” and “Back-off restarting failed container” events
3. Review logs for root cause
kubectl logs <pod> -n <ns>
kubectl logs --previous <pod>Look for app stack traces, missing files, or startup errors
4. Check recent events
kubectl get events -n <ns> --field-selector involvedObject.name=<pod>This reveals issues like failed probes, missing volumes, or resource evictions.
b. Fixing the CrashLoopBackOff Error
ImagePullBackOff means that Kubernetes repeatedly tries and fails to pull your container image, then backs off with increasing delay (5s, 10s, 20s, up to ~5min). It’s a sign that a pod can’t start because its image can’t be retrieved.

The reasons behind this error are:
apiVersion: v1
kind: Pod
metadata:
name: pull-demo
spec:
containers:
- name: pull-demo
image: ngiinx:1.14.2
restartPolicy: AlwaysHere, ngiinx:1.14.2 is a typo; Kubernetes can’t find it, so the pod reports ErrImagePull followed by ImagePullBackOff.
a. The steps you can follow to troubleshoot the ImagePullBackOff error:
1. View pod status
kubectl get pods
NAME READY STATUS RESTARTS AGE
test-pod 0/1 ErrImagePull 0 19s
NAME READY STATUS RESTARTS AGE
test-pod 0/1 ImagePullBackOff 0 52sLook for STATUS = ImagePullBackOff (often preceded by ErrImagePull)
2. Inspect pod details
kubectl describe pod <pod> -n <ns>
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 41s default-scheduler Successfully assigned default/test-pod to docker-desktop
Normal Pulling 19s (x2 over 39s) kubelet Pulling image "ngiinx:1.14.2"
Warning Failed 14s (x2 over 34s) kubelet Failed to pull image "nginx:1.14.2": Error response from daemon: pull access denied for nginx, repository does not exist or may require 'docker login': denied: requested access to the resource is denied
Warning Failed 14s (x2 over 34s) kubelet Error: ErrImagePull
Normal BackOff 3s (x2 over 34s) kubelet Back-off pulling image "nginy:1.14.2"
Warning Failed 3s (x2 over 34s) kubelet Error: ImagePullBackOffIn Events, look for messages like ErrImagePull, Repository does not exist, or pull access denied.
3. Check image pull manually
docker pull <image>:<tag> If this fails: wrong tag/name or registry issue.
If this succeeds: Kubernetes-specific problem, likely network or credentials
4. Inspect network and permissions
Test connectivity: curl registry-url from the node
Ensure imagePullSecrets are referenced correctly if using a private registry.
b. Fixing the ImagePullBackOff error

CreateContainerConfigError is an error that occurs during the creation of the container because the configuration is incorrect or something is missing in the Pod's container configuration. As a result, Kubernetes is unable to produce the necessary configuration for a container.

The common issues that cause this error:
apiVersion: v1
kind: Pod
metadata:
name: bad-config-demo
spec:
containers:
- name: app
image: nginx
envFrom:
- configMapRef:
name: missing-config
restartPolicy: NeverHere, missing-config doesn’t exist, leading to CreateContainerConfigError.
a. Steps to troubleshoot CreateContainerConfigError:
1. Check pod status
kubectl get pods
NAME READY STATUS RESTARTS AGE
my-pod 0/2 CreateContainerConfigError 1(10s ago) 28sYou’ll see STATUS = CreateContainerConfigError
2. Describe the pod and inspect events
kubectl describe pod bad-config-demo -n my-nsLook for events like:
Warning Failed 56s (x6 over 1m45s)
kubelet Error: configmap "my-configmap" not foundor similar for Secrets or volumes
3. Verify referenced resources
kubectl get configmap missing-config -n my-ns
kubectl get secret my-secret -n my-ns
kubectl get pvc my-pvc -n my-nsIf any return “NotFound,” that’s your issue.
4. Check env vars, volumes, image config
Ensure envFrom, volumeMounts, imagePullSecrets match actual resource names.
b. Fixing the CreateContainerConfigError error
kubectl create configmap missing-config --from-literal=k=v
kubectl create secret generic my-secret --from-literal=key=valCreateContainerError is an error that occurs when Kubernetes fails to create a container within a pod. It means the issue is related to the container’s creation itself.

The common reasons are:
apiVersion: v1
kind: Pod
metadata:
name: missing-cmd
spec:
containers:
- name: no-cmd
image: ubuntu:latest
command: ["nonexistentcommand"]
restartPolicy: NeverDue to the nonexistent command, you’ll hit StartError/CreateContainerError.
a. Steps to troubleshoot CreateContainerError:
1. Check pod status
kubectl get pods
NAME READY STATUS RESTARTS AGE
missing-cmd 0/1 StartError 0 32sLook for STATUS = StartError
2. Describe pod & inspect events
kubectl describe pod <pod> -n <ns>
State: Terminated
Reason: StartError
Message: failed to create containerd task: failed to create shim task: OCI runtime create failed: runc create failed: unable to start container process: error during container init: exec: "nonexistentcommand": executable file not foundSee State and Events like Warning for StartError.
3. Validate container runtime issues
If the event says command is missing, check that your image has ENTRYPOINT/CMD.
If naming conflict, clear orphaned containers on the node. For volume errors, verify PVCs and mounts exist.
4. Check node logs if necessary
If errors are container runtime-related, inspect kubelet logs on that node for deeper context.
b. Fixing the StartError:
ENTRYPOINT ["/usr/src/app/startup.sh"]or in YAML:
command: ["/usr/src/app/startup.sh"]
FailedScheduling means Kubernetes tried, but couldn’t place your pod on any node. The pod stays in a Pending state because the scheduler found no node meeting all requirements.

The reasons behind FailedScheduling include:
apiVersion: v1
kind: Pod
metadata:
name: picky-pod
spec:
containers:
- name: app
image: nginx
nodeSelector:
disktype: ssd
tolerations:
- key: "special"
operator: "Equal"
value: "true"
effect: "NoSchedule"
resources:
requests:
cpu: "4"
memory: "8Gi"If no node is labeled disktype=ssd, no node has that toleration, or no node has 4 CPU/8 Gi memory free, the pod remains in FailedScheduling.
a. Steps to troubleshoot the FailedScheduling error:
1. Check pod status and events
kubectl get pods
NAME READY STATUS RESTARTS AGE
picky-pod 0/1 Pending 0 2m26s
kubectl describe pod picky-pod -n my-ns
Events show messages like:
Warning FailedScheduling ... 0/5 nodes available: Insufficient cpu, didn't match node selector...These explain the root cause of FailedScheduling.
2. Review node resources & readiness
kubectl describe nodesLook for Unschedulable, NotReady, resource pressure (DiskPressure, MemoryPressure).
3. Inspect taints and tolerations
kubectl get nodes -o json | jq '.items[].spec.taints'Verify pod tolerates required taints or adjust accordingly.
4. Verify node selector & affinity rules
Ensure labels like disktype=ssd exist on nodes:
kubectl get nodes --show-labels If not, add a matching label or drop the selector.
5. Check PVC / volume zone issues
For pods using PVCs, confirm volume binding matches node zones to prevent PV zone conflicts.
6. Scale or add nodes
If resources are tight, scale the cluster or free up capacity. This addresses FailedScheduling due to insufficient resources.
b. Fixing FailedScheduling error:
NonZeroExitCode occurs when a container inside a Kubernetes pod starts successfully but exits with a status code other than zero. This signals that something went wrong during execution; Kubernetes detects this via the container's exit status and marks it as a NonZeroExitCode.

The reasons behind this error are:
apiVersion: v1
kind: Pod
metadata:
name: demo
spec:
containers:
- name: exit-test
image: python:3.10-alpine
command: ["python", "-c", "import sys; sys.exit(1)"]
restartPolicy: NeverThis pod exits immediately with code 1, resulting in a Kubernetes NonZeroExitCode.
a. Steps for troubleshooting the NonZeroExitCode Kubernetes error:
1. Check pod status and exit code
kubectl get pods
NAME READY STATUS RESTARTS AGE
nonzero-exit 0/1 Error 0 17s
kubectl describe pod exit-code-demo
Reason: Error
Exit Code: 1 #that’s your non-zero exit codeYou'll see lines like: Exit Code: 1, a sign of Kubernetes NonZeroExitCode.
2. Inspect container logs
kubectl logs demoLogs often pinpoint the failure reason, like config issues or script errors.
3. Review YAML manifest
Look at command, args, env, and volume mounts; typos or missing variables often cause exit code 1 or higher.
4. Validate dependencies and scripts
Ensure all necessary libraries, configs, or files are present; scripts return code 0 on success.
b. Fixing the NonZeroExitCode Kubernetes error:

OOMKilled happens when a container exceeds its allowed memory limit and the Linux kernel’s Out-Of-Memory (OOM) Killer terminates it. Kubernetes captures this in the pod’s status as OOMKilled (exit code 137), reflecting the system's protective action against memory exhaustion.

This Kubernetes error arises due to:
Exceeded memory limits: container requests more memory than specified in resources.limits.memory.
Memory leaks or unexpected usage spikes: software faults or sudden load increases push usage over limits.
Node-level memory pressure: if the node runs low on memory, the kernel may kill processes even within Kubernetes pods, to relieve pressure
Misalignment between limits and requests: Kubernetes allocates resources based on requests, but if many pods use more than requested, the node can get overcommitted, triggering OOMKilled events
apiVersion: v1
kind: Pod
metadata:
name: oom-example
spec:
containers:
- name: mem-hog
image: polinux/stress
resources:
requests:
memory: "100Mi"
limits:
memory: "200Mi"
command: ["stress"]
args: ["--vm", "1", "--vm-bytes", "250M", "--vm-hang", "1"]
restartPolicy: AlwaysThis Kubernetes pod requests 100 Mi but allows up to 200 Mi. The stress command allocates 250 Mi, triggering OOMKilled.
a. Investigate the OOMKilled Kubernetes event
1. Check the pod status
kubectl get pods
NAME READY STATUS RESTARTS AGE
oom-example 0/1 CrashLoopBackOff 4 (81s ago) 3m3sLook for pods marked as CrashLoopBackOff(because the pod keeps restarting after being killed).
2. Describe the pod
kubectl describe pod oom-example -n <namespace>
State: Waiting
Reason: CrashLoopBackOff
Last State: Terminated
Reason: OOMKilled
Exit Code: 137Look for Last State: Terminated, Reason: OOMKilled, Exit Code: 137
3. View logs
kubectl logs oom-example -n <namespace>
kubectl logs --previous oom-example -n <namespace>Check application logs for memory spikes before termination.
4. Monitor usage
kubectl top pod oom-example -n <namespace>
kubectl top nodeCompare memory usage to requests/limits.
5. Inspect node events
If it's broader node pressure rather than just container-level, you might see MemoryPressure or eviction messages
b. Fixing the OOMKilled Kubernetes issue
1. Right-size memory requests & limits
Adjust based on real app usage:
resources:
requests:
memory: "300Mi"
limits:
memory: "600Mi"This gives headroom for spikes.
PerfectScale can help you optimize resource usage straightforward and reliable. It tells you the right-sizing recommendations, apply automatically through its automation agent, which can update workloads safely without manual intervention.
›› Try PerfectScale’s PodFit now to see exactly where your workloads are over- or under-provisioned and apply right-sizing automatically.
2. Detect & fix memory leaks: Use application profiling (e.g., heap dumps, tracing) to identify slow-growing memory usage patterns.
3. Optimize your application: Consider using memory-efficient libraries or processing data in batches.
4. Use autoscaling tools: Enable a Vertical Pod Autoscaler (VPA) to adjust memory settings dynamically based on actual usage
5. Enforce constraints cluster-wide: Use Kubernetes LimitRanges or policies (e.g., Kyverno) to ensure pods don’t miss resource limits.
6. Horizontal scaling or dedicated nodes: Spread workload across replicas or deploy memory-heavy pods on nodes with ample RAM.
NodeNotReady in Kubernetes means a node within your cluster can't run workloads and is marked unschedulable. This tells Kubernetes that the node is temporarily incapable of hosting pods, and the control plane won't schedule new pods there until it's healthy again. The status is set by the Node Controller after missing heartbeats or failing health conditions like DiskPressure, MemoryPressure, or NetworkUnavailable.

NodeNotReady error is due to:
System resource exhaustion: Running low on CPU, memory, disk, or encountering PID limits.
kubelet service failures: When the kubelet crashes, stops, or misconfigures, the node loses its heartbeat to Kubernetes.
kube-proxy or CNI issues: Networking agents malfunctioning can disrupt communication.
Network connectivity loss: Partitioned networks or API-server timeouts make Kubernetes mark the node NotReady.
Node-level pressure or eviction: If all memory is consumed by pods, a node may become unresponsive and transition to NodeNotReady.
a. Investigate the NodeNotReady Kubernetes event
1. List Kubernetes nodes
kubectl get nodes
NAME STATUS ROLES AGE VERSION
node2 NotReady <none> 25d v1.32.1Spot any nodes with NotReady status.
2. Dive into node details
kubectl describe node node2
Conditions:
Type Status Reason Message
---- ------ ------ —-----
MemoryPressure True KubeletHasInsufficientMemory kubelet
has insufficient memory available
DiskPressure False KubeletHasNoDiskPressure kubelet
has no disk pressure
PIDPressure False KubeletHasSufficientPID
kubelet has sufficient PID available
Ready False KubeletNotReady
Node is under memory pressureFocus on Conditions (MemoryPressure, DiskPressure, NetworkUnavailable, KubeletNotReady) and Events.
3. Check kube-system components
kubectl get pods -n kube-system --field-selector spec.nodeName=node2Confirm support pods like kube-proxy, CNI, or CSI sidecars haven’t failed.
b. Fixing the NodeNotReady error in Kubernetes
ping node-ip
traceroute node-ip
An Unauthorized error in Kubernetes means the API server doesn't recognize the identity you’re using, no valid credentials (e.g., missing token or client cert). A Forbidden error means Kubernetes knows who you are but you're not allowed to perform the requested action, based on RBAC rules.

In Kubernetes, these RBAC errors occur due to:
Incorrect or missing credentials: Unauthorized shows up when there's no service account token, invalid user certificate, or kubeconfig context mismatch.
Missing Role / ClusterRoleBinding: Even if authenticated, lacking permissions means Kubernetes throws Forbidden.
Namespaced resource issues: Binding a Role in one namespace but trying to access resources in another leads to Forbidden errors.
a. Investigate the Unauthorized / Forbidden RBAC error
1. Confirm the error type
Unauthorized = credentials issue. Forbidden = identity known but insufficient permissions.
2. Validate identity and context
kubectl config current-context
kubectl config view --minify
kubectl auth can-i get pods -n defaultIf can-i returns “no”, it's RBAC; if it errors due to unknown user, likely credentials issue.
3. Inspect existing roles and bindings
kubectl get roles,rolebindings -n default
kubectl get clusterroles,clusterrolebindingsEnsure your user or serviceAccount is bound correctly.
4. Check namespace scope
Ensure RoleBindings target resources in the correct namespace. Using RoleBinding in the default won’t work for other namespaces.
b. Fixing the Unauthorized / Forbidden RBAC error in Kubernetes
1. Fix unauthorized (identity) issues
Ensure kubeconfig has correct user entry (client cert, token).
Refresh the expired client certificate or token.
Make sure you’re using the intended context or ServiceAccount with --as.
2. Grant missing permissions using Role / ClusterRole
Example Role + RoleBinding for read-only pod access:
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: default
name: pod-reader
rules:
- apiGroups: [""]
resources: ["pods"]
verbs: ["get", "list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
namespace: default
name: alice-pod-reader
subjects:
- kind: User
name: alice@example.com
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: Role
name: pod-reader
apiGroup: rbac.authorization.k8s.ioApply:
kubectl apply -f rolebinding.ymlThis ensures Kubernetes user “alice” has proper pod access.
3. Use ClusterRoleBindings when needed cluster-wide
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: cluster-admin-binding
subjects:
- kind: User
name: adminuser
apiGroup: rbac.authorization.k8s.io
roleRef:
kind: ClusterRole
name: cluster-admin
apiGroup: rbac.authorization.k8s.io
4. Correct namespace in RoleBinding
If you’re operating in namespace prod, ensure your RoleBinding is in prod, not default and the Role belongs there.
A YAML misconfiguration in Kubernetes refers to errors in your manifest files such as wrong indentation, incorrect types, invalid APIs, typos, or missing required fields, that lead to failed deployments, silent misbehavior, or unexpected pod failures.

Common causes of Kubernetes YAML misconfigurations include:
Indentation errors: Mixing spaces and tabs or inconsistent spacing leads to invalid structure.
Wrong data types: Supplying strings instead of integers (e.g., port: "80" vs. port: 80) causes Kubernetes to reject or silently misparse fields.
Typos in keys: Misspelling apiVersion, metadata, or resource names causes subtle failures or missing resources .
Incorrect API version: Older or unsupported API versions (e.g., apps/v1beta1) lead to Kubernetes ignoring specs or failing kubectl apply.
Missing or mis-nested fields: Required spec keys missing or nested incorrectly (e.g., no containers: block), leading to invalid Kubernetes objects.
Invalid resource relationships: Broken reference between objects (e.g., Deployment referring to a ServiceAccount that doesn’t exist) causes failed or incomplete deployment

apiVerion: apps/v1
kind: Deployment
metadata:
name: demo-app
spec:
replicas: "3"
template:
metadata:
labels:
app: demo
spec:
containers:
- image: nginx
name: nginx
ports:
- containerPort: "80"In above configuration, replicas and containerPort are strings instead of integers and apiVersion is misspeled. In this case, Kubernetes reject the manifest.
a. Investigate Kubernetes YAML errors
1. Dry-run validation
kubectl apply --dry-run=client -f manifest.yamlThis flags schema and validation errors proactively.
2. Lint YAML files
Use tools like yamllint, kubeconform, or monokle to catch indentation issues, wrong types, missing fields, or typos before deploying.
3. Enable CI/CD manifest validation
Incorporate YAML validation in pipelines, kubectl apply --dry-run and kubeval, so errors stop the CI job rather than hitting Kubernetes clusters .
b. Fixing Kubernetes YAML misconfiguration
1. Correct types and formatting
Ensure integers for numeric fields:
replicas: 3
ports:
- containerPort: 80
2. Consistent indentation
Always use spaces (e.g. 2 or 4 spaces consistently). Avoid tabs. YAML parsers often can’t detect invisible tab errors .
3. Double-check API versions and resource fields
Make sure you use valid apiVersion for the cluster version, and include required fields like spec.template for Deployments.
4. Validate references
Confirm that referenced resources exist e.g. ConfigMaps, secrets, ServiceAccounts spelled exactly as they appear in Kubernetes.
5. Integrate YAML linters and schema validators in your GitOps or CI/CD workflow, using tools like kubeconform, yamllint, or Monokle for validation before deployment .
6. Version control and code reviews
Store all Kubernetes manifests in Git. Peer review helps catch typos, mis-indexed fields, and logic flaws before production deployment
With PerfectScale, teams don’t just discover issues when it’s too late, they gain real-time visibility into 30+ critical reliability, performance, and cost errors across their Kubernetes environments. The platform not only highlights these misconfigurations and inefficiencies but also provides actionable, prioritized remediation steps. This means you can move from firefighting to proactively ensuring stability, efficiency, and cost control, keeping your clusters always in the Perfect state. Start a Free Trial today and Book a Demo with the PerfectScale Team!


Install in minutes and instantly receive actionable intelligence.





.jpg)

