Table of Content
Subscribe to our newsletter
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.

Kubernetes cost management is the ongoing process of tracking, allocating, and reducing what you spend to run your clusters. Most teams overspend not because Kubernetes is expensive by default, but because resources are set and forgotten.
Here is what you need to know:
Effective cost management combines visibility, governance, and automation. Visibility without automation means manual work that does not scale. Automation without visibility means you cannot prove the savings.
Kubernetes cost management involves monitoring, allocating, and optimizing infrastructure expenses by tracking resource usage at the pod, namespace, or label level. Key strategies include setting resource quotas/limits, utilizing spot instances for non-critical workloads, enabling auto-scaling, and implementing tools like Kubecost or OpenCost for granular visibility into CPU, memory, and network spend.
Key cost optimization strategies:
Common cost drivers:
This is part of a series of articles about Kubernetes cost optimization
In this article:
Idle resources are a major source of unnecessary costs in Kubernetes environments. These occur when compute resources such as CPU or memory are allocated to pods or nodes but are not actively used by workloads. This can happen when developers overestimate resource needs or when applications scale down but allocated resources are not reclaimed. As a result, organizations continue paying for infrastructure that provides little value to active workloads.
To address idle resource costs, organizations should conduct regular audits and monitor cluster utilization. Identifying and decommissioning idle nodes or pods can free resources for other workloads or allow infrastructure downsizing. Automated tools can detect and alert teams to underutilized resources.
Inter-zone data transfer costs arise when data moves between availability zones within the same cloud region. In Kubernetes, this can occur when pods communicate across zones or when persistent volumes are accessed from nodes in different zones. Cloud providers charge for data transfer between zones, and these fees can accumulate if applications are not designed with data locality in mind.
To reduce inter-zone data transfer costs, align workloads and their storage resources within the same zone when possible. Kubernetes affinity and anti-affinity rules can help schedule pods close to their data sources. Monitoring network traffic patterns and understanding how applications interact across zones can reveal optimization opportunities.
Persistent volumes, load balancers, and network services are common in Kubernetes deployments, but they can increase costs if not managed carefully. Persistent volumes, especially those using high-performance storage classes, can be expensive when overprovisioned or left unused. Each load balancer provisioned by Kubernetes services typically incurs ongoing charges, even if the service is rarely accessed.
Network costs can increase due to high outbound data transfer, excessive internal traffic, or inefficient service architectures. To control these expenses, teams should review storage and networking configurations regularly. Deleting unused persistent volumes, consolidating load balancer usage, and optimizing network policies can reduce ongoing costs.
Overprovisioning CPU and memory is common in Kubernetes environments, often due to conservative resource requests and limits. When pods request more resources than they use, the scheduler reserves those resources, reducing cluster utilization and increasing infrastructure costs. This can lead to higher spending without improvements in application performance or reliability.
To reduce overprovisioning, organizations should use monitoring and analysis tools to compare requested and actual usage. Historical usage data can guide more accurate resource requests and limits, helping teams right-size workloads. Regular reviews and adjustments improve the efficiency of cluster operations and reduce waste.
Tracking the right metrics helps teams understand where Kubernetes costs originate and how efficiently resources are used. These metrics support identifying waste, improving workload efficiency, and making informed decisions about scaling and infrastructure planning. Continuous monitoring of cost-related indicators helps control spending without affecting application performance or reliability.
Right-sizing resources involves aligning resource requests and limits for pods and workloads with actual usage patterns. Many organizations overestimate their needs, which leads to wasted capacity and higher cloud bills. By analyzing historical usage data, teams can set more accurate resource values so applications have what they need without overprovisioning.
Right-sizing requires continuous monitoring and periodic adjustments. Automated tools can recommend or enforce optimal resource settings based on real-time and historical metrics. Regular right-sizing reduces costs and improves cluster density and utilization.
Auto-scaling adjusts the number of pod replicas or nodes in response to workload demand. Kubernetes provides features such as the horizontal pod autoscaler (HPA) and cluster autoscaler to automate scaling decisions. Increasing resources during peak loads and reducing them during low-demand periods helps control costs while maintaining performance.
Successful auto-scaling depends on properly configured policies and thresholds. Monitoring application metrics and adjusting settings helps ensure scaling actions align with operational needs. Combined with right-sizing, auto-scaling supports a cost-conscious Kubernetes environment.
Spot instances are discounted cloud compute resources offered by providers such as AWS, Azure, and Google Cloud. They are available at lower prices than on-demand instances but can be interrupted with little notice. Running fault-tolerant workloads or batch jobs on spot instances can reduce infrastructure costs.
To use spot instances safely, workloads should tolerate interruptions. Kubernetes supports node pools and taints, allowing teams to schedule suitable workloads on spot nodes while reserving on-demand nodes for critical services. Monitoring availability and automating responses to interruptions helps maintain reliability.
Namespace quotas are Kubernetes policies that limit the amount of resources, such as CPU, memory, and storage, that can be consumed within a namespace. Setting quotas prevents teams or applications from consuming excessive resources and increasing costs.
Implementing namespace quotas requires understanding typical usage patterns and setting realistic limits. Regular reviews and updates help balance cost control with operational flexibility. Namespace quotas support efficient management of multi-tenant Kubernetes environments.
A labeling strategy uses Kubernetes labels to tag resources by team, project, environment, or cost center. Labels enable detailed cost allocation and reporting, allowing infrastructure expenses to be attributed to the appropriate stakeholders.
Consistent labeling simplifies monitoring and automation. Organizations should define and enforce label standards and integrate labeling into deployment pipelines and policies. Clear labeling improves visibility into spending and supports cost analysis.
Deleting idle resources involves identifying and removing unused or underutilized components such as pods, nodes, volumes, or load balancers. Idle resources contribute directly to unnecessary cloud spending and can accumulate over time.
Automated cleanup processes and alerts help maintain cluster hygiene, ensuring that idle resources are removed without requiring constant manual checks. Regular audits and integration with cost management tools can surface idle resources so teams can remove them.
Related content: Read our guide to Kubernetes cost monitoring (coming soon)

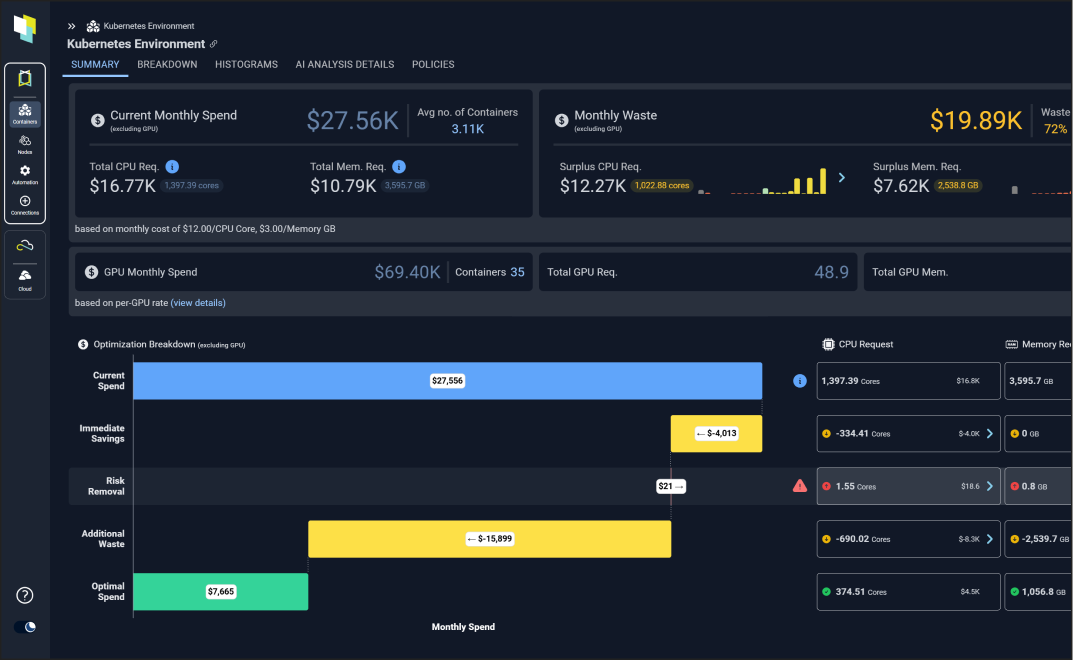
PerfectScale by DoiT is an automated Kubernetes optimization and management platform that continuously right-sizes workloads, eliminates waste, and keeps clusters stable without manual effort. It analyzes resource usage across every workload and autonomously adjusts CPU and memory configurations to reduce cloud costs by up to 50% while maintaining 99.99% availability.
Key features include:
Start optimizing your Kubernetes costs with PerfectScale

CAST AI is a Kubernetes optimization platform focused on reducing cloud infrastructure costs through automation. It analyzes cluster usage and adjusts compute resources to improve utilization and reduce waste. The platform combines autoscaling, bin packing, spot instance automation, and workload migration to optimize performance and spending.
Key features include:
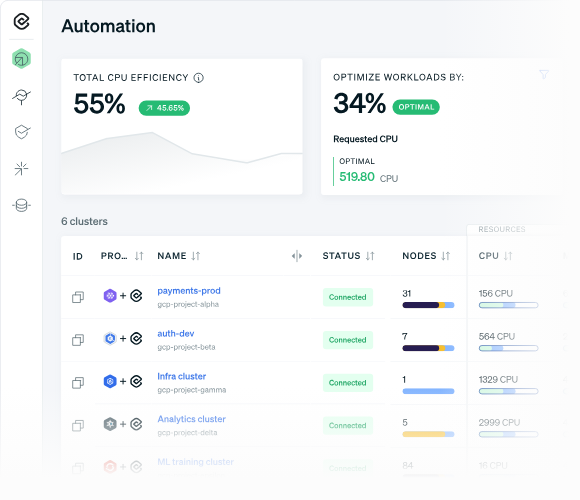
Source: CAST AI

Kubex is a Kubernetes and AI infrastructure optimization platform that improves resource efficiency, application performance, and cloud cost management through automation. The platform uses AI and machine learning models to analyze workload behavior, adjust cluster elasticity, and automate infrastructure decisions within defined guardrails.
Key features include:
Source: Kubex

OpenCost is an open source Kubernetes cost monitoring and allocation platform that provides visibility into cloud infrastructure and container spending. As a vendor-neutral project, OpenCost helps organizations measure and analyze Kubernetes costs across cloud and on-premises environments. The platform integrates with cloud billing APIs and Kubernetes resource data to deliver cost breakdowns at the cluster, namespace, pod, and container level.
Key features include:
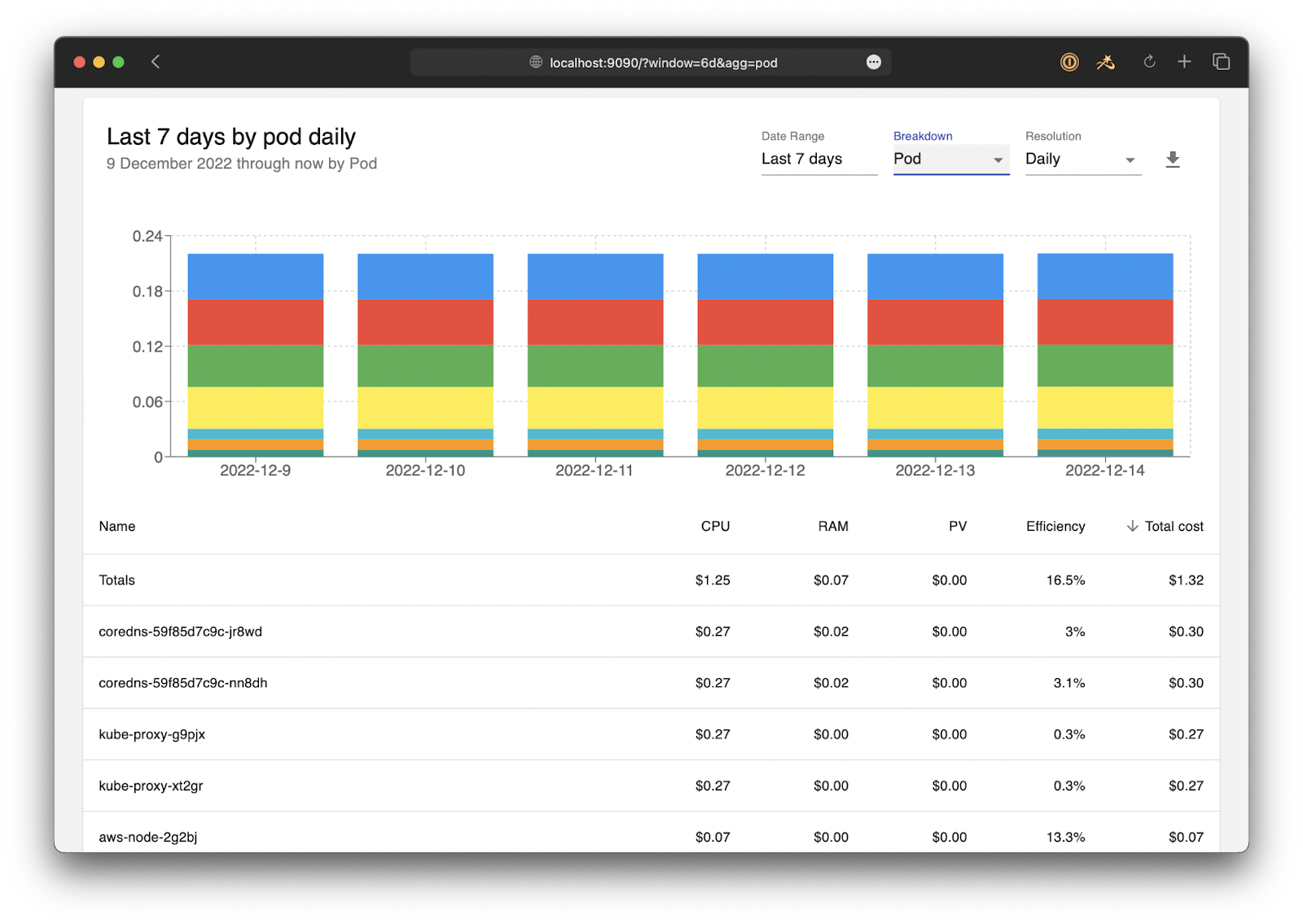
Source: OpenCost

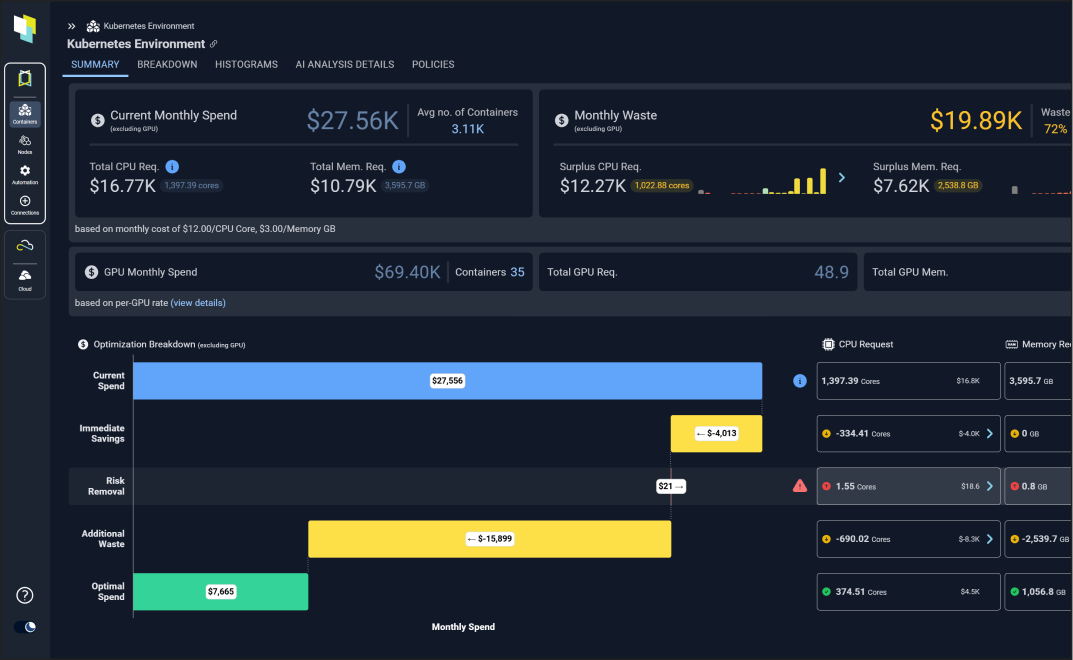
IBM Kubecost is a Kubernetes cost monitoring and optimization platform that helps organizations understand and control cloud infrastructure spending across Kubernetes environments. It provides real-time cost visibility, allocation, optimization recommendations, and governance capabilities for multi-cloud, hybrid, and on-premises deployments.
Key features include:
Source: Kubecost

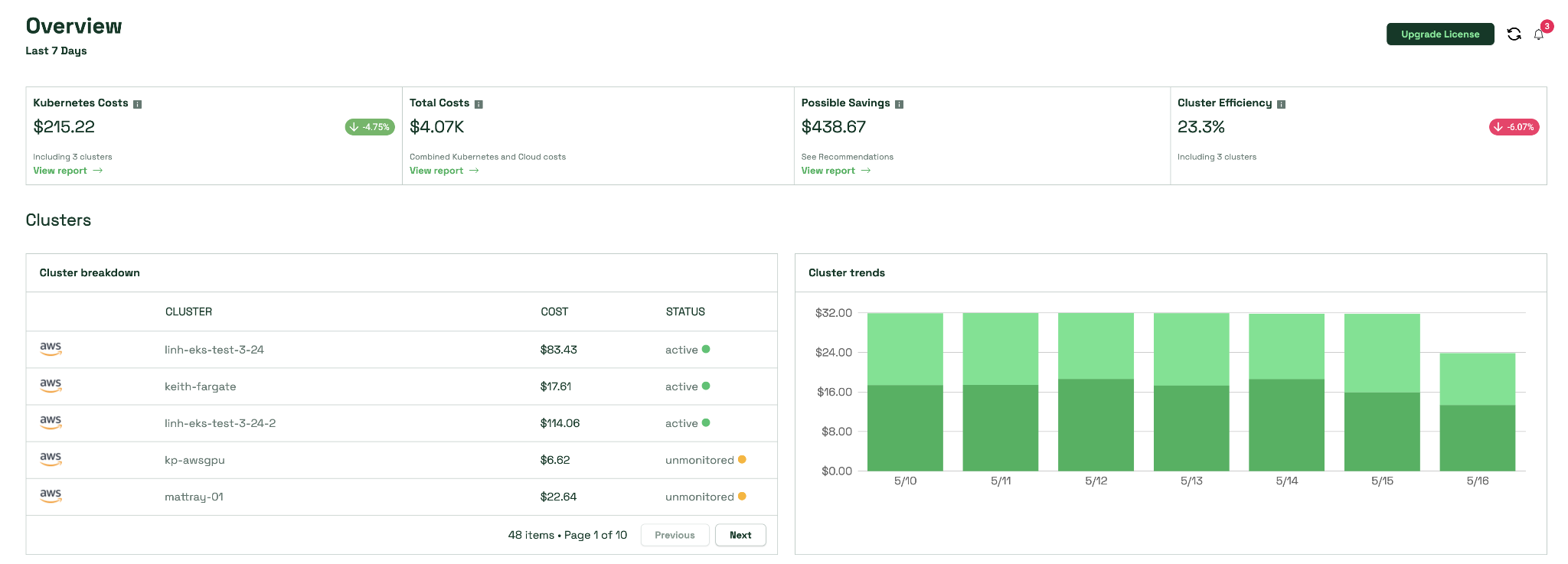
CloudZero is a cloud cost intelligence platform that provides Kubernetes cost visibility and connects infrastructure spending to business metrics. The platform helps organizations allocate Kubernetes costs, combine them with overall cloud spend, and analyze usage at granular levels such as clusters, namespaces, labels, and pods.
Key features include:
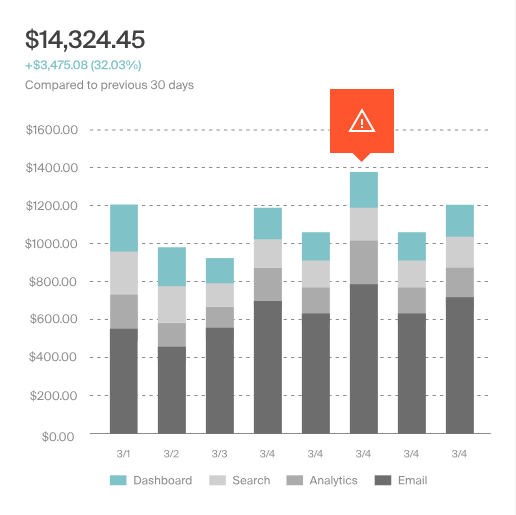
Source: CloudZero
Related content: Read our guide to Kubernetes cost optimization tools (coming soon)
Managing Kubernetes costs requires continuous visibility into how infrastructure resources are consumed across clusters, workloads, and teams. Costs often increase due to idle resources, overprovisioned CPU and memory, unnecessary storage allocations, and inefficient scaling behavior. Effective cost management combines monitoring, governance, and automation to improve resource utilization without affecting application reliability.
Kubernetes cost management is the practice of monitoring, allocating, and optimizing the infrastructure costs that come from running Kubernetes clusters. It covers tracking resource usage at the pod, namespace, and label level, identifying where money is being wasted, and applying strategies to reduce spend without hurting application performance.
It goes beyond reading a cloud bill. General cloud billing tools show you what AWS, GCP, or Azure charged you in total. Kubernetes cost management tools break that down to show you which workloads, teams, namespaces, or deployments are responsible for specific costs - and what you can do about it.
The four most common sources of unnecessary Kubernetes spend are:
Of these, over-provisioning is the most common and the easiest to fix with the right tooling.
The ten metrics that give you the clearest picture of cost efficiency are:
Most Kubernetes cost problems trace back to resource requests that were set once and never updated. As workloads change, those settings drift further from reality - and the waste compounds.
PerfectScale by DoiT fixes this automatically. It continuously analyzes CPU and memory usage across every workload in your cluster and right-sizes requests and limits in real time. It also detects the conditions that silently inflate your bill - idle node capacity, misconfigured autoscalers, OOM kills, and CPU throttling - and remediates them before they become incidents. Customers typically cut Kubernetes cloud costs by up to 50%.
Start optimizing your Kubernetes costs with PerfectScale
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}