Maximize K8s node autoscaling through optimized workloads
- Identifying and fixing workload configuration errors
- Autonomous right-sizing workloads and improving bin-packing
- Fine-tuning autoscaling group setup and selecting the proper node types for workloads
Are you scaling your Kubernetes nodes efficiently?
Node autoscalers like Karpenter and Cluster Autoscaler are powerful tools for scaling nodes up and down based on demand. They improve clusters' availability and reduce idle costs. However, even if autoscaling is well-configured, teams may often run into the following challenges:
Over-provisioned containers
Waste capacity and force autoscaler to provision more nodes than necessary.
Under-provisioned containers
Lead to reliability issues like pod evictions, node pressure, and workloads instability.
Inefficient bin-packing
Reduces efficiency by leaving resources underutilized and triggering unnecessary scaling events.
Boost autoscaling with autonomous workload
right-sizing and performance visibility
Fix configuration errors proactively
By continuously analyzing your workloads, identify and address configuration errors, such as CPU Request Not Set, Memory Request Not Set, and Memory Limit Not Set, to prevent unpredictable evictions, node over-commitment, and inefficient autoscaling.
Learn more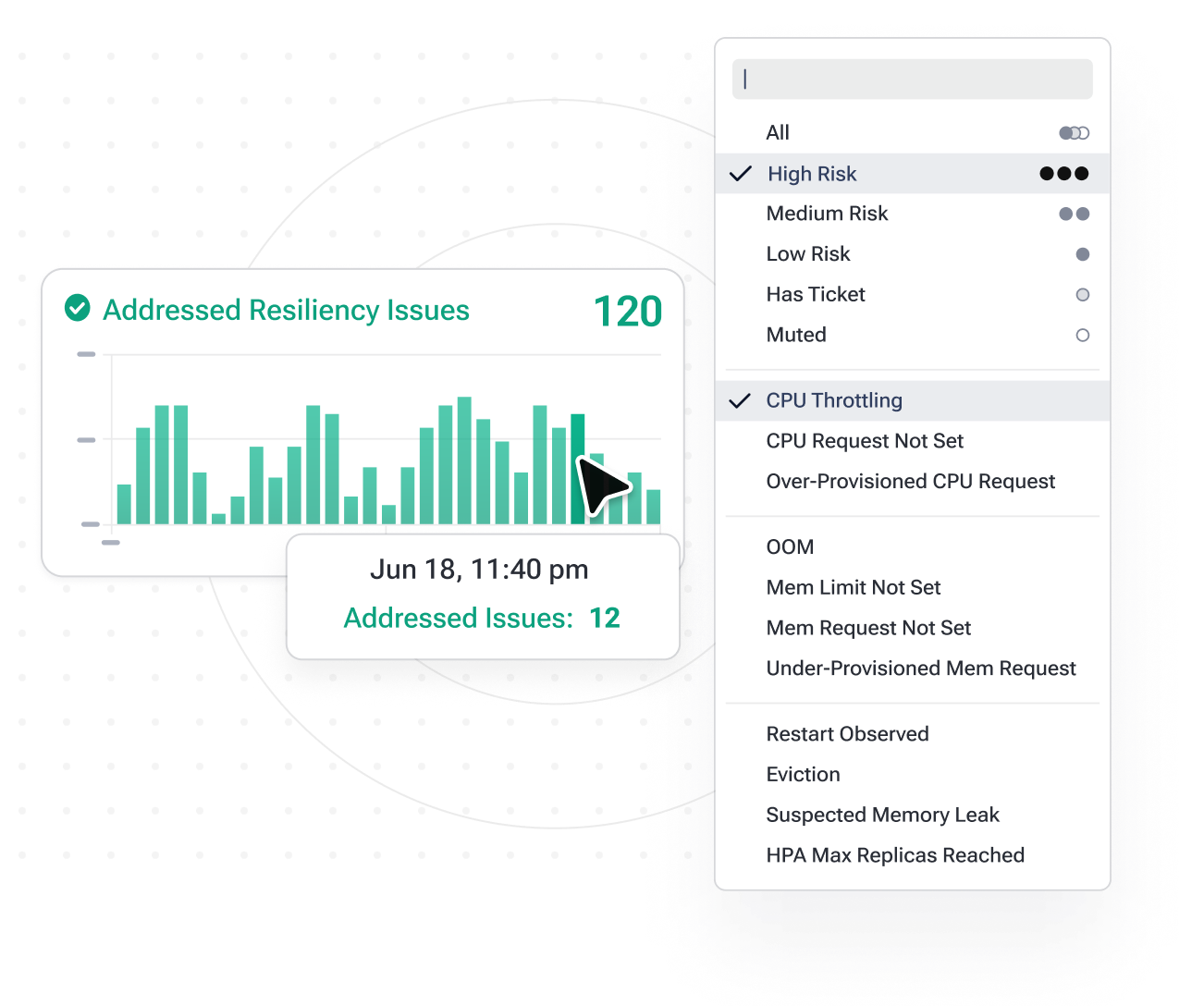
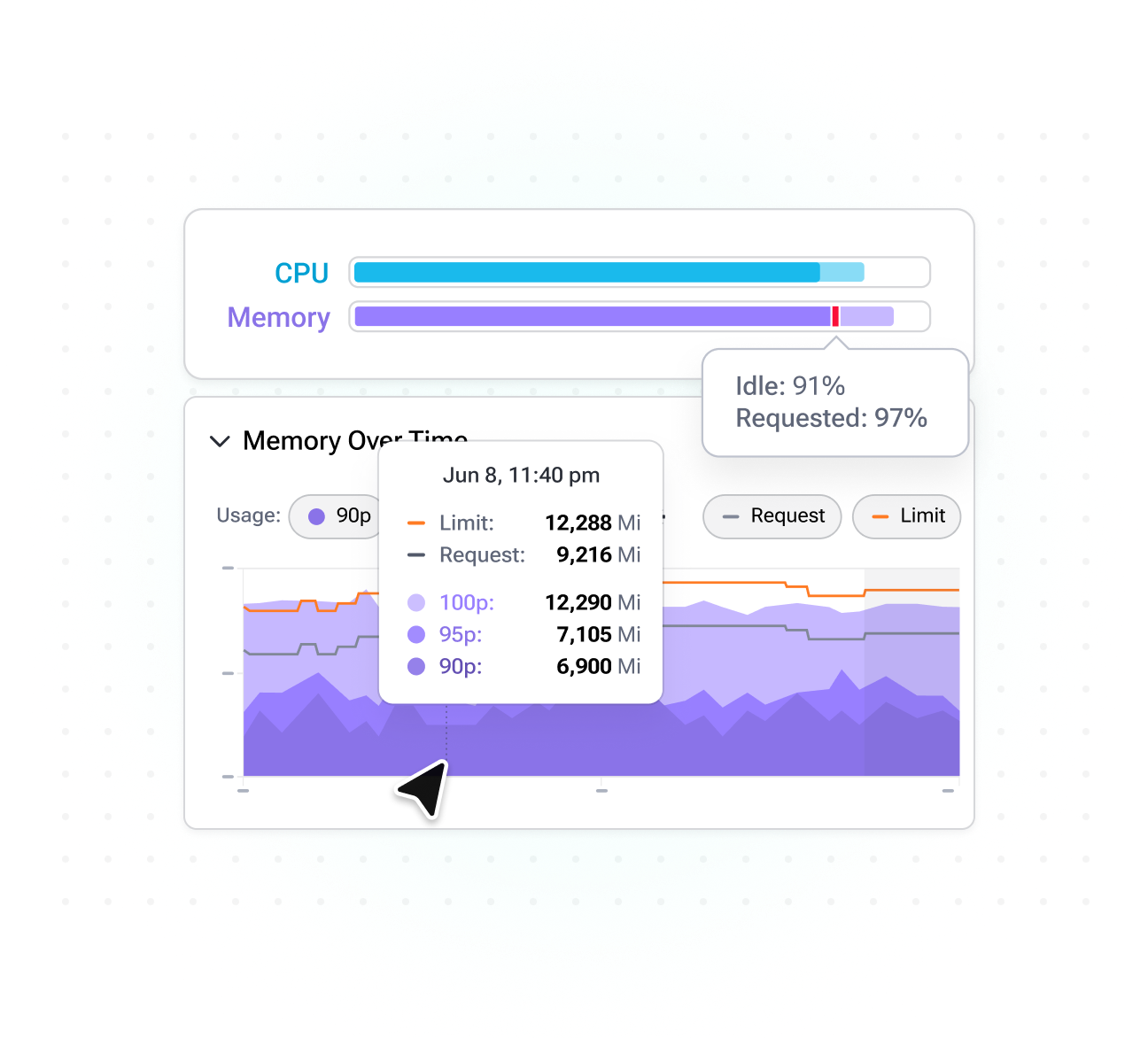
Right-size workloads autonomously
Instantly adjusts workloads’ resources based on actual utilization and improve pod bin-packing to boost autoscaling efficiency - all without manual interaction.
Maximize K8s autoscaling efficiency
Get exceptional visibility into the costs and utilization of your autoscaling groups and node pools, identify inefficiencies, and select optimal node types to improve utilization, achieve precise resource distribution, and maximize cost efficiency.

Install in minutes and instantly receive actionable intelligence.