Maximize Cost Savings by Putting Your Kubernetes Resources to Sleep During Off-Hours


In the current era of cloud computing, businesses heavily depend on container orchestration platforms such as Kubernetes to effectively handle their workloads. Kubernetes facilitates the scalability, adaptability, and robustness of applications. Nevertheless, there are situations where organizations find it advantageous to shut down their Kubernetes workloads outside regular hours. This could primarily be driven by cost-efficiency, security considerations, or the need for maintenance.
The off-hours challenge can be solved from multiple perspectives, but the two main ones that come to mind are:
- Powering off the Kubernetes nodes
- Powering off the Kubernetes applications
The former (1) might be a good solution for some, because it simply makes sure that the nodes are powered off. Essentially, nothing can be more cost effective and secure than that. However, this solution takes away the dynamic behavior of Kubernetes workloads.
In this article, I will explore 3 ways to automatically shut down Kubernetes applications. The last one being a “Bonus” for the tech-savvy.
- Cron Scaler
- Custom Metric Scaler
- Network Scaler*

Kubernetes KEDA for Event-Driven Autoscaling
KEDA is a Kubernetes-based Event Driven Autoscaler. With KEDA, you can drive the scaling of any container in Kubernetes based on the number of events needing to be processed.
An Event can be anything that is generated from an action. It could be an API call, a message in a queue, a filesystem change etc. In our case, while evaluating ways to scale to-and-from 0, the “event” is either “time” itself, or a sleep request. KEDA augments the functionality of the native Kubernetes Horizontal Pod Autoscaler (HPA) by managing it.
However, as you might be aware, HPA cannot scale workloads to 0. KEDA, however, can! By deleting the HPA completely and recreating it if necessary.
In order for KEDA to scale your workloads to “0” during off-hours, we're going to explore a few methodologies. The first is simply time based, and the second allows you to control the sleep schedule of your precious workloads with more granularity. The third implements an immature but clever solution to this problem, using a custom resource called a “Network Scaler”.
NOTE: The code examples for the below guide are available in our GitHub Repository.
The Simple Solution — Cron Scaler
The main KEDA CRD (Custom Resource Definition) is called ScaledObject. The ScaledObject defines how many replicas a certain workload (Deployment, StatefulSet, etc) has at a specific time. As of writing this article, The Cron Scaler currently has issues when specifying what off-hours are. But, it can dictate what the on-hours are, so that your workloads know when to be awake, and otherwise — sleep.
Let’s assume you have a simple deployment, and you issue the following command in the terminal: kubectl apply -f deployment.yaml:
Now, let’s add a ScaledObject KEDA CRD and attach it to our sleep workload (your timezone can be found here). Let’s assume you want this workload alive from 9:00 AM — 17:00 PM on New York time.
When you apply this into your Namespace, you’ll see how your sleep-workload sleeps and wakes up on a schedule. This solution is simple and elegant.
(KEDA calculates the replica count of all triggers based on a MAX function. If you add another scale to the triggers array, your CRON will be used as the minimum replica count, and any addition could surpass it)
The Extensive Solution — Custom Metrics API
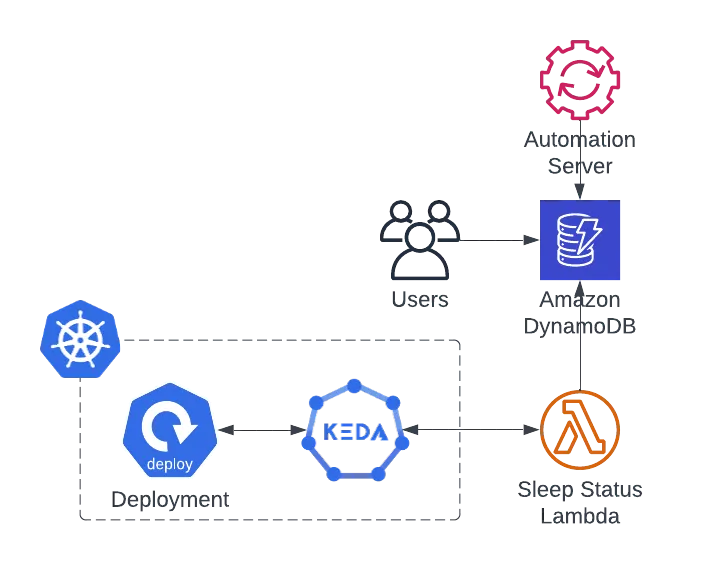
What if you wanted an external system to dictate when and how workloads sleep, and you wanted your workloads to be aware of such state and act accordingly. That is where Metrics API Scaler comes into play.
This scaler allows you to define an external endpoint for KEDA to query in order to adjust to the amount of replicas it should have.
In this use case, I have used AWS DynamoDB, AWS Lambda and Jenkins as an automation server and cron scheduler. You could however, switch in-place any of these technologies with any other Database+API Server+Automation Scheduler you choose.
The Cron scaler is not part of this solution. For this one, we implement our business logic behind a custom API endpoint, pointed at by the KEDA Metrics Scaler:
In this example, our sleepy-workload scaler points at an external URL, and provides it with two Query Parameters:
- Workload = The workload’s name (you could switch Workload with Namespace to turn off an entire namespace, having all your workloads point to the same endpoint with the same query, which is their common Namespace).
- Replicas = If I am not asleep, how many replicas should I have?
The metrics scaler then expects the following JSON response from the GET request if the workload is Awake:
And if the workload is considered Asleep
Let’s assume we have the following DynamoDB table called state-of-my-workloads:
.png)
I have written a pseudo-code that allows your workload to be awoken and be put to sleep. Let’s write a simple Python Lambda that answers the precise inquiry KEDA is requesting. You could implement and deploy any API server your’e familiar with that is suited to your technology stack and use case:
The get_sleep_value() can be implemented in the following way, if let’s say, you keep the state of your workloads/namespaces in AWS DynamoDB:
In this function, we return the Boolean value of the sleep status of your workload. In return, the main function returns the amount of replicas provided by the replicas query parameter.
Now, you could use any automation solution to switch your Boolean sleep value in your workload’s state table, or connect it to a manual portal in which people can turn their workloads on and off on-demand.
The Clever Solution — Network Scaler
The KEDA Network Scaler is and has been on a Beta status for years. Regardless, it’s an exciting add-on challenging one of the most popular scaling problems in the world — network traffic. By monitoring the metric of network traffic as opposed to just compute, we are opening ourselves to a whole new range of capabilities. One of those is, as you guessed it — down-scaling. This is an example of an implementation of the “serverless” pattern on Kubernetes.
That means, that if your workload has a network endpoint, it will scale from 0 to 1, upon being called. It’s the perfect metaphor for knocking on the workload’s door and waking it up.
To get started, you need to add the KEDA http add-on to your existing KEDA installment in the cluster:
While working with HTTP, you’d obviously need a Kubernetes Service to point to your workloads:
And now comes the magic. Because you installed the HTTP add-on, you now have the following CRD available. You can configure it as such (addon version v0.7):
What happens now, is that the http-add-on operator will pick up the CRD and when it’s done configuring, you’ll see a new Service that’s ready to route HTTP traffic to your Deployment. In order to connect the http-add-on service to your workload’s service, there is one last action that needs doing.
It is important to note that the routing of the add-on service behaves similar to an ingress, and has the possibility of combining itself with the ingress, as per the official doc. That means that it routes traffic based on Hostnames and Paths. For our demo purposes, we’ll mimic this capability by using only the ClusterIP type of Service.
We can now test this mechanism by port-forwarding HTTP traffic to this service, and you’ll see it waking up and auto-scaling as per the min/max you’ve .
In order to do that, you’d have to first expose the new service, so we’ll do that with port-forward:
And in another terminal:
And viola!
_____________________
This article has listed several ways of using KEDA as a mechanism to achieve down-scaling to 0. There are many more methods out there and there is no right or wrong answer. These solutions are simply using logic that already exists in open-source in order to achieve this goal. If you have any other suggestions I’d love to read them in the comments, alongside any questions you might have.
Amitai G is a freelance DevOps consultant with an extensive background in DevOps practices and Kubernetes' ongoing maintenance and operations. As the author of the @elementtech.dev Medium channel, he specializes in writing articles that provide engineers with a deeper understanding and best practice guidance across the various aspects of the Cloud Native landscape.

.png)

.png)





