.png)
It’s hard to believe that we are already in February! So far this year, the PerfectScale development team has been busy, releasing several impactful features. Let's take a look some some of the major releases built to help improve your cost visibility, identify and react to resilience issues quicker, and more efficiently manage your alerts.
Node-Level Trends
To give you a more granular view of the overtime cost trends of your machines, we have released new Node-level stack-by criteria in our trend reporting. This gives you a different dimension of visibility, allowing you to more efficiently analyze cost spikes and the effectiveness of all the machines throughout your clusters. This enhancement allows you to stack your cost reports by:
- Node Group: Segmenting by your pre-established Node Groups .
- Node Type: Segmenting by the types of nodes throughout your environment.
- Node Reservation: Segmenting your nodes by Spots vs On-demand instances.

With this new layer to Trends, you can now build reports that help you:
- Analyze and optimize scaling configs for node groups - such as min, max, and desired group size.
- Analyze and improve your spot (preemptible) VM usage efficiency.
- Build effective configs for Karpenter-managed Node Pools.
New Resilience Risk Indicators
We have added two additional resilience risk indicators to the Podfit Status dropdown, allowing you to quickly filter your view to show which workloads are impacted by these issues. The new risk indicators are:

1. Evictions: In many cases, severe CPU throttling or OOM can cause your pod to be evicted from the Node. By filtering your Podfit view to workloads that have observed evictions, you can better prioritize which ones need your attention to improve the stability of your environment.
2. HPA at Max Replicas Observed: This indicator shows you when a workload has hit the maximum configured replicas during horizontal scaling, meaning it hits a point where it will no longer be able to scale. The severity level of this indicator is reflected by the amount of runtime the workload is using its maximum replicas, helping you prioritize the workloads that more urgently need more replicas configured.
Alerts Acknowledgements
To streamline how you manage PerfectScale alerts, we adding the ability to acknowledge alerts from the Alerts Overview page. With one click you can let your team know that you are taking ownership in evaluating the alert, avoiding redundant efforts, and providing complete visibility to which alerts are being handled, and which ones need attention.
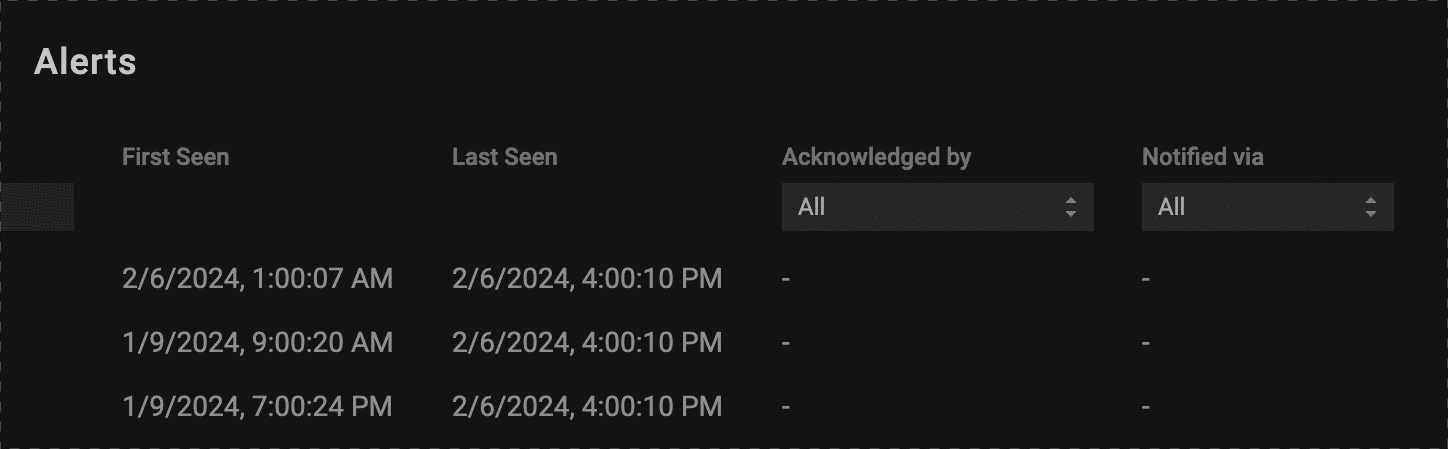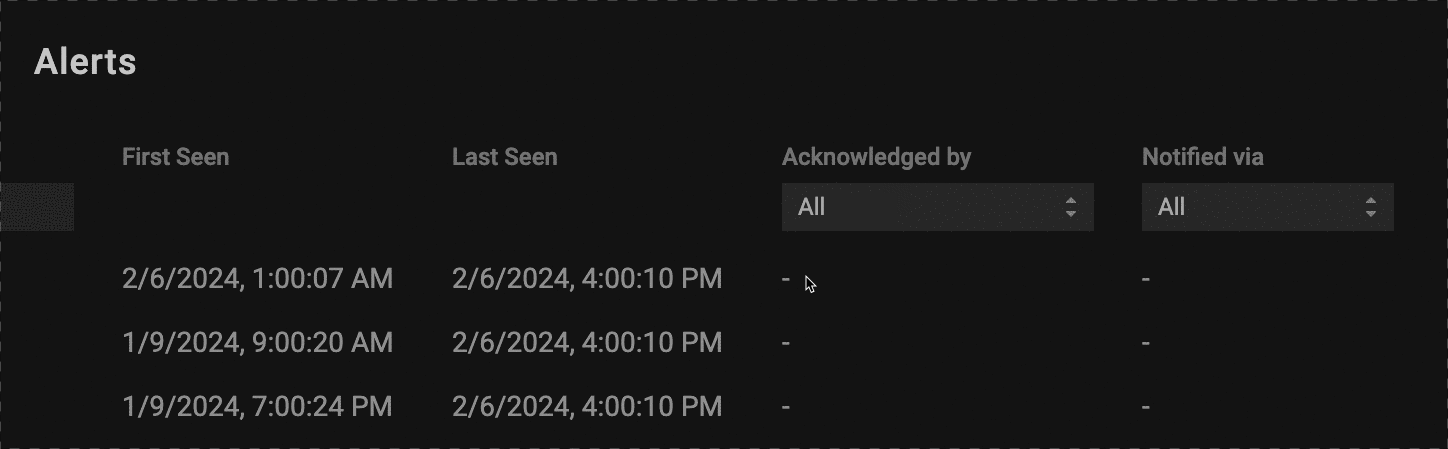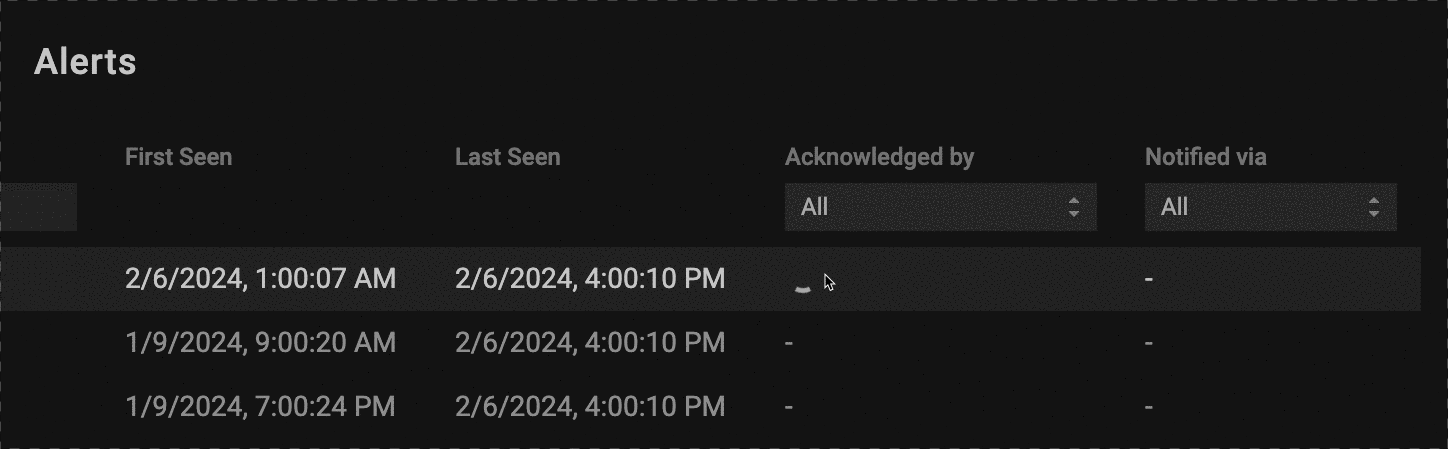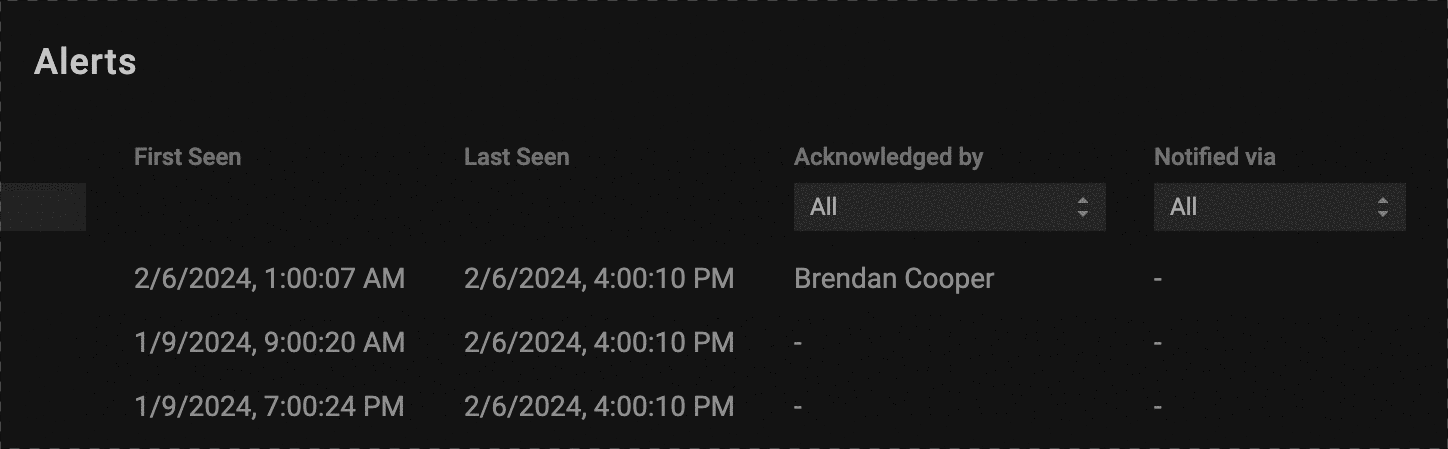
Acknowledging and alert will also send a Slack or Teams notification to the proper channel if you have the integrations set up, giving your team real-time visibility when someone takes ownership over an issue.
For more details on our latest enhancements, and all the other capabilities of PerfectScale, visit our documentation portal.

.png)
.png)
.png)





